 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Satellite Imagery for Rare Objects: An Empirical Comparison of Models and Metrics
Paper and Code
Sep 02, 2024
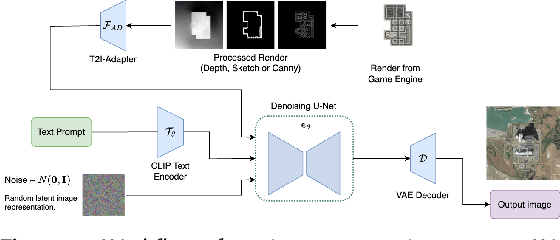
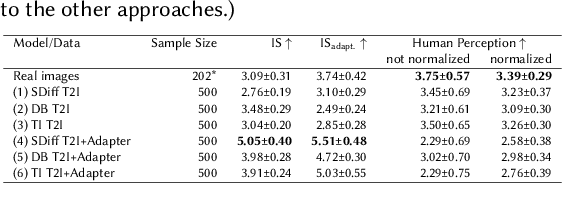

Generative deep learning architectures can produce realistic, high-resolution fake imagery -- with potentially drastic societal implications. A key question in this context is: How easy is it to generate realistic imagery, in particular for niche domains. The iterative process required to achieve specific image content is difficult to automate and control. Especially for rare classes, it remains difficult to assess fidelity, meaning whether generative approaches produce realistic imagery and alignment, meaning how (well) the generation can be guided by human input. In this work, we present a large-scale empirical evaluation of generative architectures which we fine-tuned to generate synthetic satellite imagery. We focus on nuclear power plants as an example of a rare object category - as there are only around 400 facilities worldwide, this restriction is exemplary for many other scenarios in which training and test data is limited by the restricted number of occurrences of real-world examples. We generate synthetic imagery by conditioning on two kinds of modalities, textual input and image input obtained from a game engine that allows for detailed specification of the building layout. The generated images are assessed by commonly used metrics for automatic evaluation and then compared with human judgement from our conducted user studies to assess their trustworthiness. Our results demonstrate that even for rare objects, generation of authentic synthetic satellite imagery with textual or detailed building layouts is feasible. In line with previous work, we find that automated metrics are often not aligned with human perception -- in fact, we find strong negative correlations between commonly used image quality metrics and human ratings.