Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in NLI: Ways To Go Beyond Simple Heuristics
Paper and Code
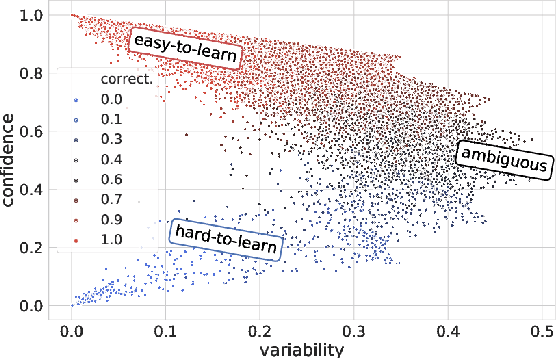
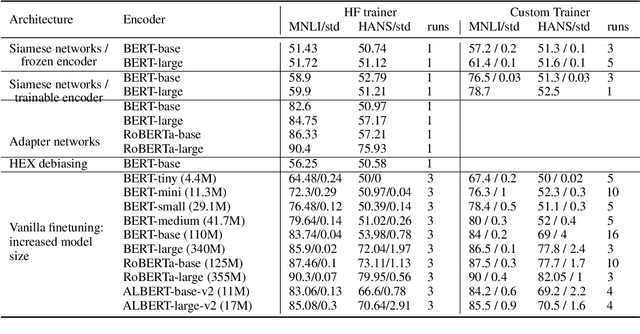
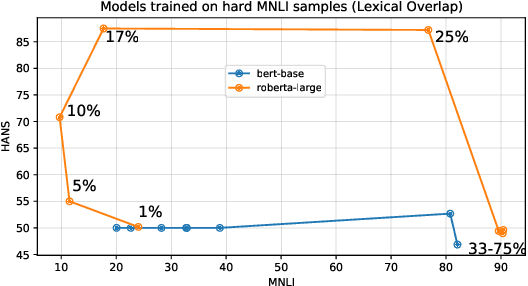
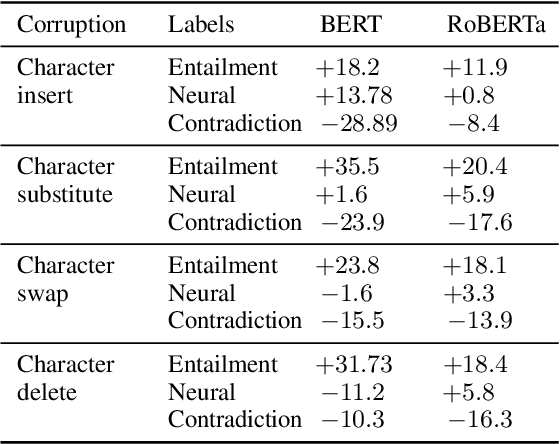
Much of recent progress in NLU was shown to be due to models' learning dataset-specific heuristics. We conduct a case study of generalization in NLI (from MNLI to the adversarially constructed HANS dataset) in a range of BERT-based architectures (adapters, Siamese Transformers, HEX debiasing), as well as with subsampling the data and increasing the model size. We report 2 successful and 3 unsuccessful strategies, all providing insights into how Transformer-based models learn to generalize.
* Workshop on Insights from Negative Results (EMNLP 2021)
View paper on