 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralisable and distinctive 3D local deep descriptors for point cloud registration
Paper and Code
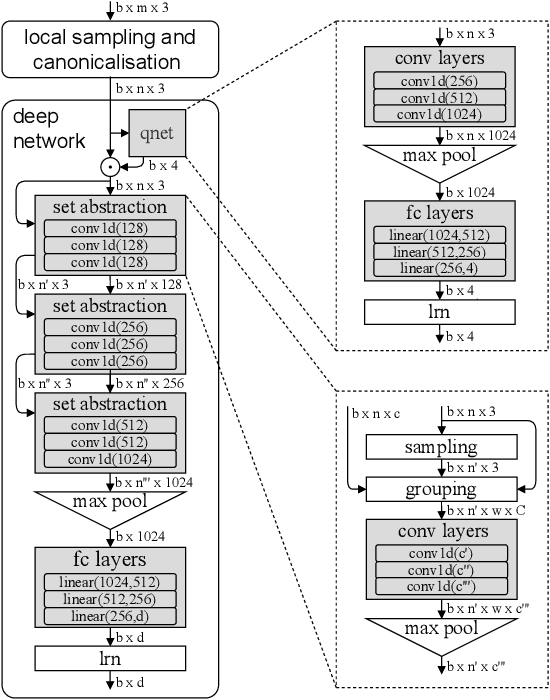


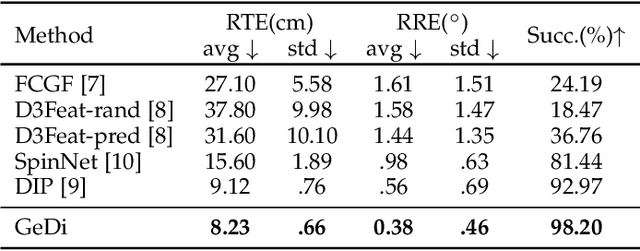
An effective 3D descriptor should be invariant to different geometric transformations, such as scale and rotation, repeatable in the case of occlusions and clutter, and generalisable in different contexts when data is captured with different sensors. We present a simple but yet effective method to learn generalisable and distinctive 3D local descriptors that can be used to register point clouds captured in different contexts with different sensors. Point cloud patches are extracted, canonicalised with respect to their local reference frame, and encoded into scale and rotation-invariant compact descriptors by a point permutation-invariant deep neural network. Our descriptors can effectively generalise across sensor modalities from locally and randomly sampled points. We evaluate and compare our descriptors with alternative handcrafted and deep learning-based descriptors on several indoor and outdoor datasets reconstructed using both RGBD sensors and laser scanners. Our descriptors outperform most recent descriptors by a large margin in terms of generalisation, and become the state of the art also in benchmarks where training and testing are performed in the same scenarios.