 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGene Expression based Survival Prediction for Cancer Patients: A Topic Modeling Approach
Paper and Code
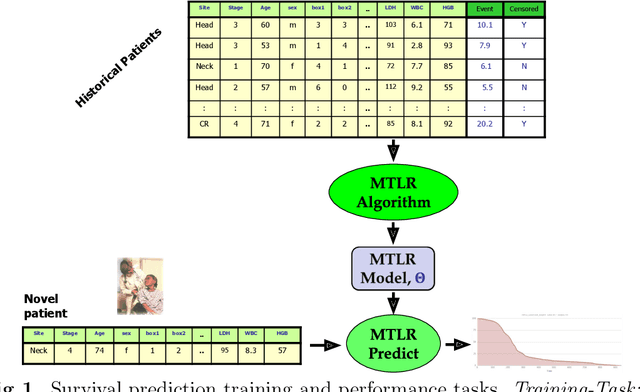
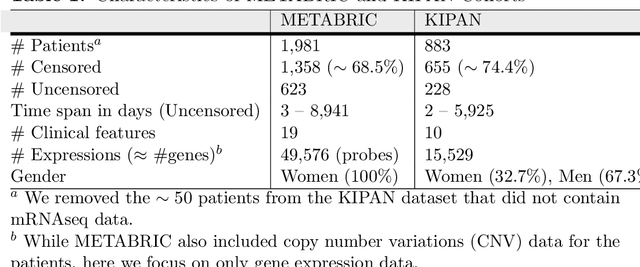
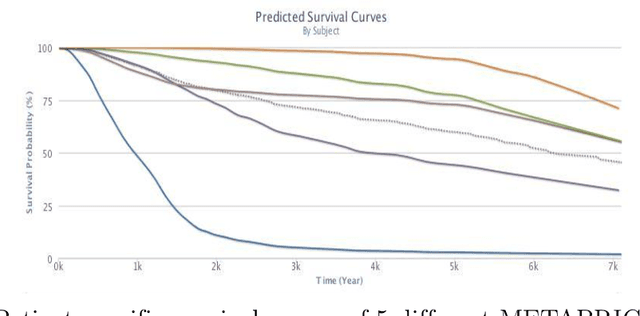
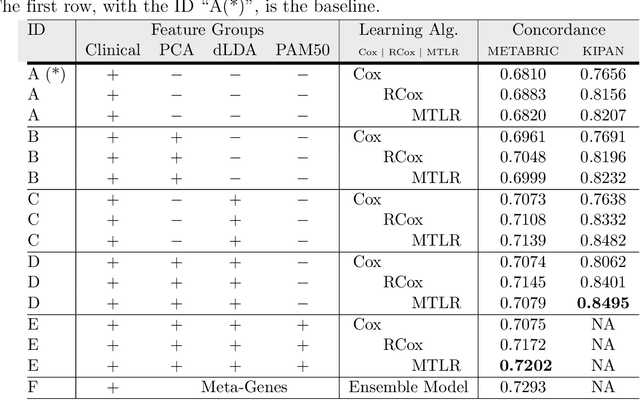
Cancer is one of the leading cause of death, worldwide. Many believe that genomic data will enable us to better predict the survival time of these patients, which will lead to better, more personalized treatment options and patient care. As standard survival prediction models have a hard time coping with the high-dimensionality of such gene expression (GE) data, many projects use some dimensionality reduction techniques to overcome this hurdle. We introduce a novel methodology, inspired by topic modeling from the natural language domain, to derive expressive features from the high-dimensional GE data. There, a document is represented as a mixture over a relatively small number of topics, where each topic corresponds to a distribution over the words; here, to accommodate the heterogeneity of a patient's cancer, we represent each patient (~document) as a mixture over cancer-topics, where each cancer-topic is a mixture over GE values (~words). This required some extensions to the standard LDA model eg: to accommodate the "real-valued" expression values - leading to our novel "discretized" Latent Dirichlet Allocation (dLDA) procedure. We initially focus on the METABRIC dataset, which describes breast cancer patients using the r=49,576 GE values, from microarrays. Our results show that our approach provides survival estimates that are more accurate than standard models, in terms of the standard Concordance measure. We then validate this approach by running it on the Pan-kidney (KIPAN) dataset, over r=15,529 GE values - here using the mRNAseq modality - and find that it again achieves excellent results. In both cases, we also show that the resulting model is calibrated, using the recent "D-calibrated" measure. These successes, in two different cancer types and expression modalities, demonstrates the generality, and the effectiveness, of this approach.