 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCExplainer: Human-in-the-Loop Concept-based Explanations for Graph Neural Networks
Paper and Code
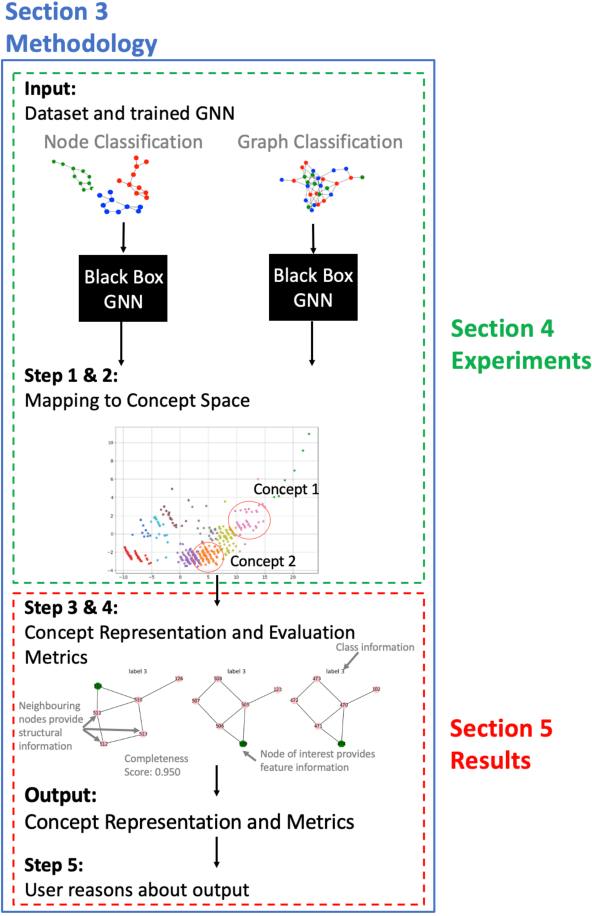
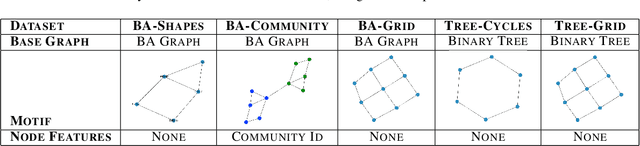
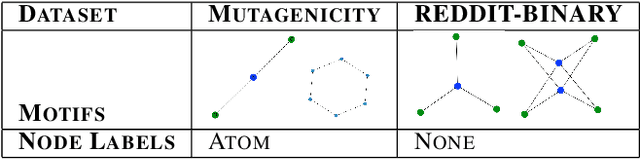
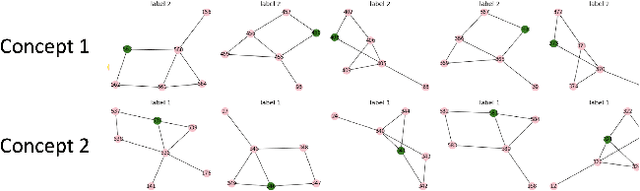
While graph neural networks (GNNs) have been shown to perform well on graph-based data from a variety of fields, they suffer from a lack of transparency and accountability, which hinders trust and consequently the deployment of such models in high-stake and safety-critical scenarios. Even though recent research has investigated methods for explaining GNNs, these methods are limited to single-instance explanations, also known as local explanations. Motivated by the aim of providing global explanations, we adapt the well-known Automated Concept-based Explanation approach (Ghorbani et al., 2019) to GNN node and graph classification, and propose GCExplainer. GCExplainer is an unsupervised approach for post-hoc discovery and extraction of global concept-based explanations for GNNs, which puts the human in the loop. We demonstrate the success of our technique on five node classification datasets and two graph classification datasets, showing that we are able to discover and extract high-quality concept representations by putting the human in the loop. We achieve a maximum completeness score of 1 and an average completeness score of 0.753 across the datasets. Finally, we show that the concept-based explanations provide an improved insight into the datasets and GNN models compared to the state-of-the-art explanations produced by GNNExplainer (Ying et al., 2019).