 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian variational approximation with sparse precision matrices
Paper and Code
Apr 13, 2017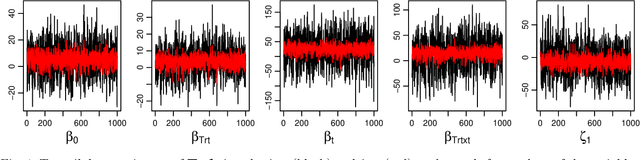
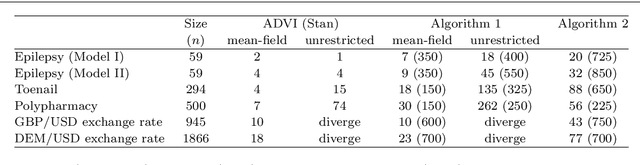
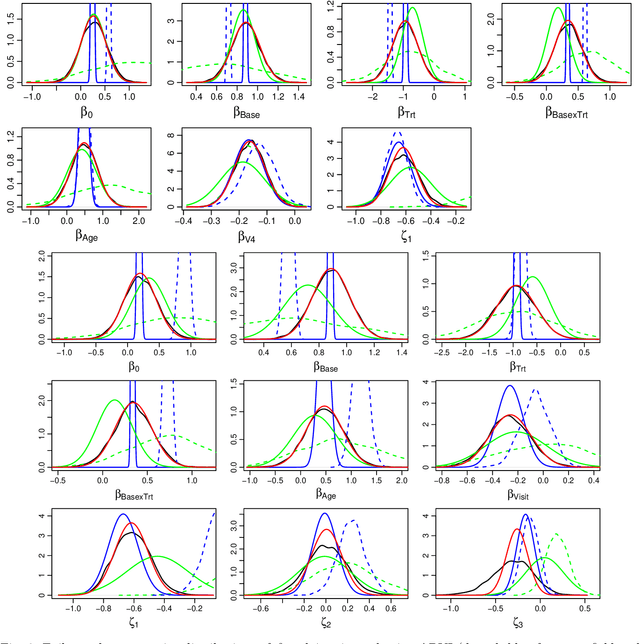
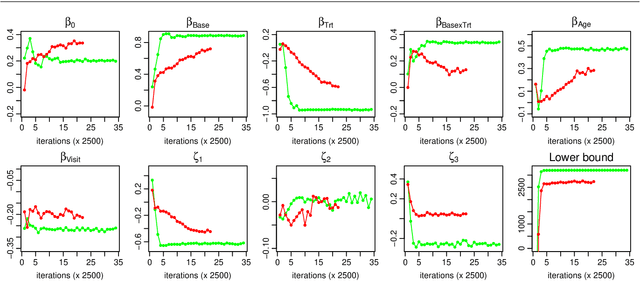
We consider the problem of learning a Gaussian variational approximation to the posterior distribution for a high-dimensional parameter, where we impose sparsity in the precision matrix to reflect appropriate conditional independence structure in the model. Incorporating sparsity in the precision matrix allows the Gaussian variational distribution to be both flexible and parsimonious, and the sparsity is achieved through parameterization in terms of the Cholesky factor. Efficient stochastic gradient methods which make appropriate use of gradient information for the target distribution are developed for the optimization. We consider alternative estimators of the stochastic gradients which have lower variation and are more stable. Our approach is illustrated using generalized linear mixed models and state space models for time series.