 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-RCN: Optimizing the Gap between Classification and Localization Tasks for Object Detection
Paper and Code
Nov 14, 2020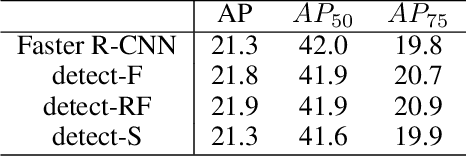
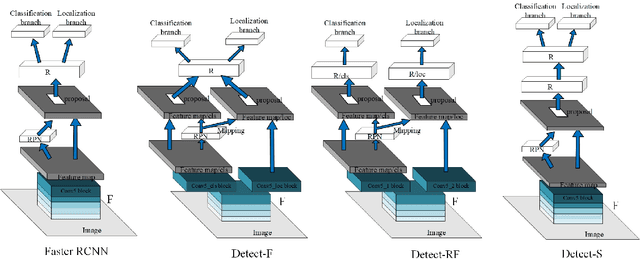
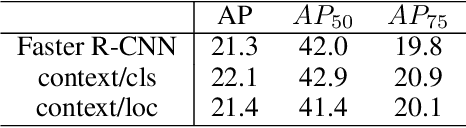
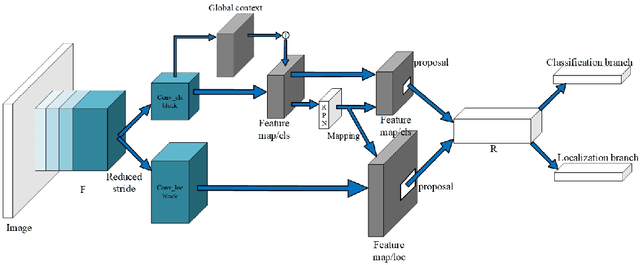
Multi-task learning is widely used in computer vision. Currently, object detection models utilize shared feature map to complete classification and localization tasks simultaneously. By comparing the performance between the original Faster R-CNN and that with partially separated feature maps, we show that: (1) Sharing high-level features for the classification and localization tasks is sub-optimal; (2) Large stride is beneficial for classification but harmful for localization; (3) Global context information could improve the performance of classification. Based on these findings, we proposed a paradigm called Gap-optimized region based convolutional network (G-RCN), which aims to separating these two tasks and optimizing the gap between them. The paradigm was firstly applied to correct the current ResNet protocol by simply reducing the stride and moving the Conv5 block from the head to the feature extraction network, which brings 3.6 improvement of AP70 on the PASCAL VOC dataset and 1.5 improvement of AP on the COCO dataset for ResNet50. Next, the new method is applied on the Faster R-CNN with backbone of VGG16,ResNet50 and ResNet101, which brings above 2.0 improvement of AP70 on the PASCAL VOC dataset and above 1.9 improvement of AP on the COCO dataset. Noticeably, the implementation of G-RCN only involves a few structural modifications, with no extra module added.