 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) Network
Paper and Code
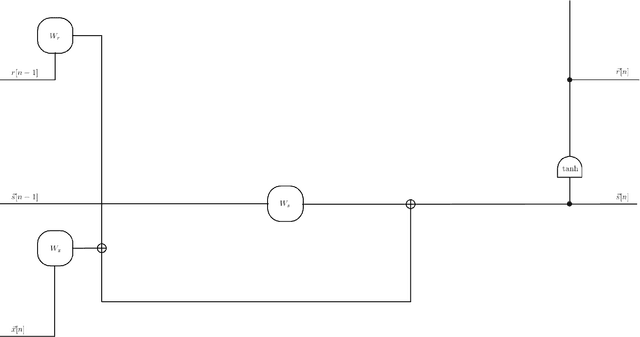
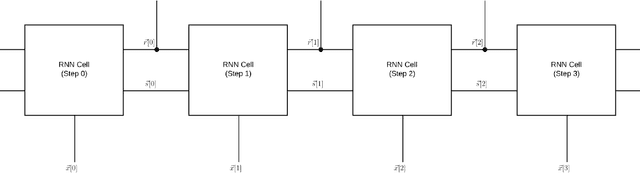
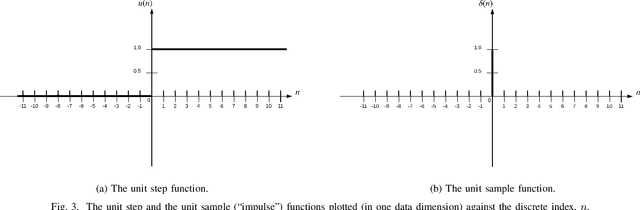

Because of their effectiveness in broad practical applications, LSTM networks have received a wealth of coverage in scientific journals, technical blogs, and implementation guides. However, in most articles, the inference formulas for the LSTM network and its parent, RNN, are stated axiomatically, while the training formulas are omitted altogether. In addition, the technique of "unrolling" an RNN is routinely presented without justification throughout the literature. The goal of this paper is to explain the essential RNN and LSTM fundamentals in a single document. Drawing from concepts in signal processing, we formally derive the canonical RNN formulation from differential equations. We then propose and prove a precise statement, which yields the RNN unrolling technique. We also review the difficulties with training the standard RNN and address them by transforming the RNN into the "Vanilla LSTM" network through a series of logical arguments. We provide all equations pertaining to the LSTM system together with detailed descriptions of its constituent entities. Albeit unconventional, our choice of notation and the method for presenting the LSTM system emphasizes ease of understanding. As part of the analysis, we identify new opportunities to enrich the LSTM system and incorporate these extensions into the Vanilla LSTM network, producing the most general LSTM variant to date. The target reader has already been exposed to RNNs and LSTM networks through numerous available resources and is open to an alternative pedagogical approach. A Machine Learning practitioner seeking guidance for implementing our new augmented LSTM model in software for experimentation and research will find the insights and derivations in this tutorial valuable as well.