 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Rank No More: Low-Rank Weight Training for Modern Speech Recognition Models
Paper and Code
Oct 10, 2024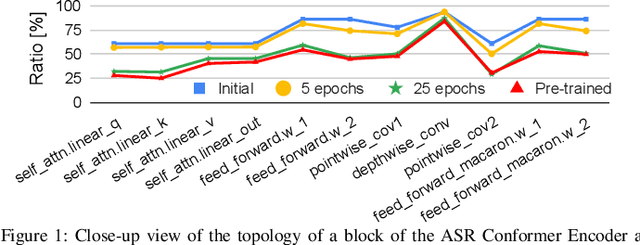
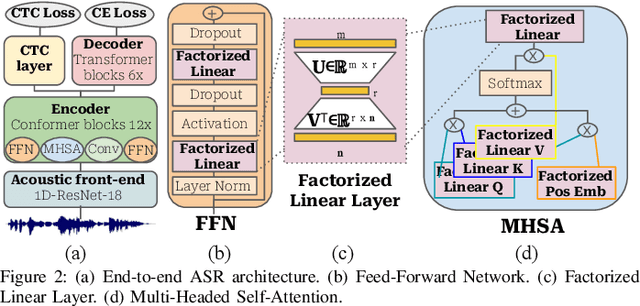
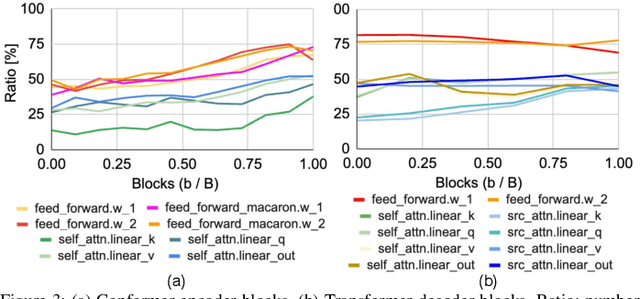
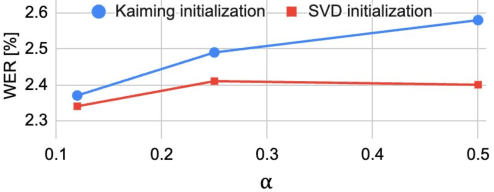
This paper investigates the under-explored area of low-rank weight training for large-scale Conformer-based speech recognition models from scratch. Our study demonstrates the viability of this training paradigm for such models, yielding several notable findings. Firstly, we discover that applying a low-rank structure exclusively to the attention modules can unexpectedly enhance performance, even with a significant rank reduction of 12%. In contrast, feed-forward layers present greater challenges, as they begin to exhibit performance degradation with a moderate 50% rank reduction. Furthermore, we find that both initialization and layer-wise rank assignment play critical roles in successful low-rank training. Specifically, employing SVD initialization and linear layer-wise rank mapping significantly boosts the efficacy of low-rank weight training. Building on these insights, we introduce the Low-Rank Speech Model from Scratch (LR-SMS), an approach that achieves performance parity with full-rank training while delivering substantial reductions in parameters count (by at least 2x), and training time speedups (by 1.3x for ASR and 1.15x for AVSR).