 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrustratingly Simple Pretraining Alternatives to Masked Language Modeling
Paper and Code
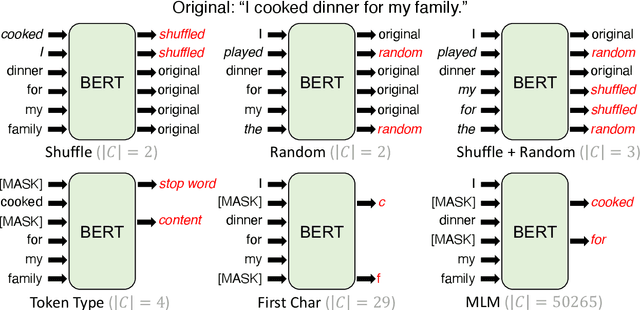
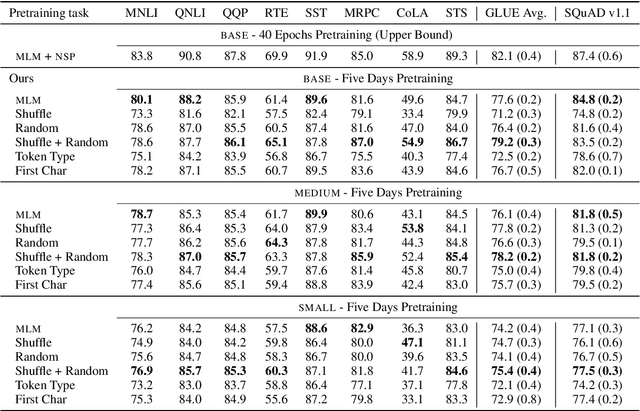
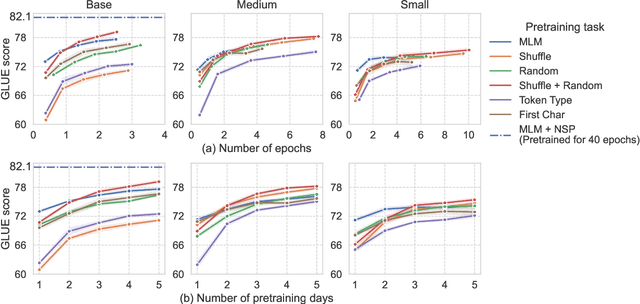
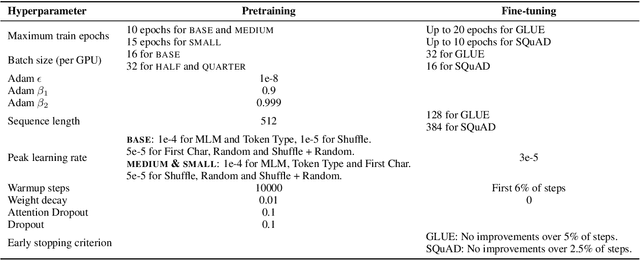
Masked language modeling (MLM), a self-supervised pretraining objective, is widely used in natural language processing for learning text representations. MLM trains a model to predict a random sample of input tokens that have been replaced by a [MASK] placeholder in a multi-class setting over the entire vocabulary. When pretraining, it is common to use alongside MLM other auxiliary objectives on the token or sequence level to improve downstream performance (e.g. next sentence prediction). However, no previous work so far has attempted in examining whether other simpler linguistically intuitive or not objectives can be used standalone as main pretraining objectives. In this paper, we explore five simple pretraining objectives based on token-level classification tasks as replacements of MLM. Empirical results on GLUE and SQuAD show that our proposed methods achieve comparable or better performance to MLM using a BERT-BASE architecture. We further validate our methods using smaller models, showing that pretraining a model with 41% of the BERT-BASE's parameters, BERT-MEDIUM results in only a 1% drop in GLUE scores with our best objective.