 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFront Contribution instead of Back Propagation
Paper and Code
Jun 10, 2021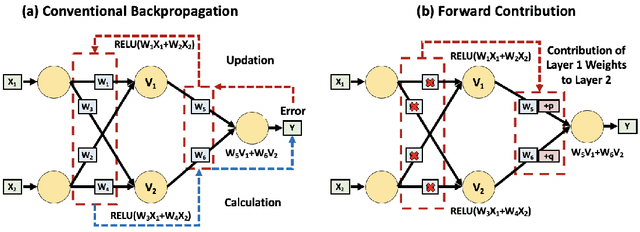
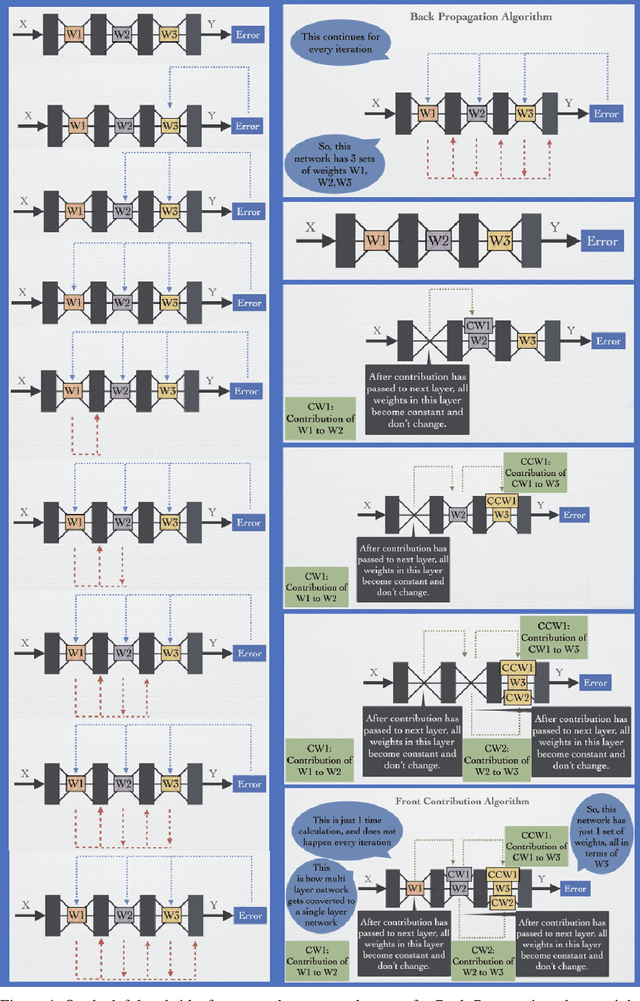
Deep Learning's outstanding track record across several domains has stemmed from the use of error backpropagation (BP). Several studies, however, have shown that it is impossible to execute BP in a real brain. Also, BP still serves as an important and unsolved bottleneck for memory usage and speed. We propose a simple, novel algorithm, the Front-Contribution algorithm, as a compact alternative to BP. The contributions of all weights with respect to the final layer weights are calculated before training commences and all the contributions are appended to weights of the final layer, i.e., the effective final layer weights are a non-linear function of themselves. Our algorithm then essentially collapses the network, precluding the necessity for weight updation of all weights not in the final layer. This reduction in parameters results in lower memory usage and higher training speed. We show that our algorithm produces the exact same output as BP, in contrast to several recently proposed algorithms approximating BP. Our preliminary experiments demonstrate the efficacy of the proposed algorithm. Our work provides a foundation to effectively utilize these presently under-explored "front contributions", and serves to inspire the next generation of training algorithms.