 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Spelling to Grammar: A New Framework for Chinese Grammatical Error Correction
Paper and Code

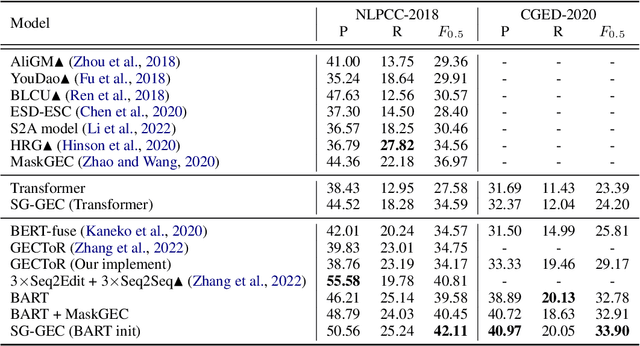
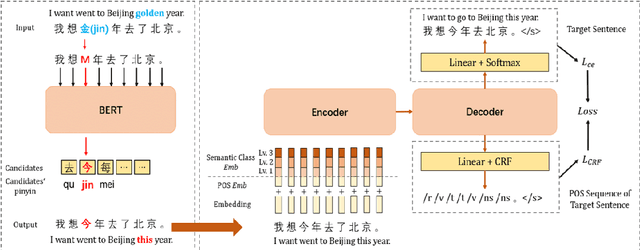
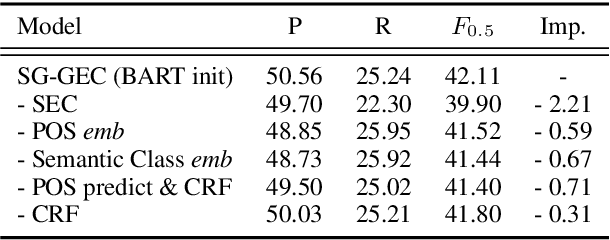
Chinese Grammatical Error Correction (CGEC) aims to generate a correct sentence from an erroneous sequence, where different kinds of errors are mixed. This paper divides the CGEC task into two steps, namely spelling error correction and grammatical error correction. Specifically, we propose a novel zero-shot approach for spelling error correction, which is simple but effective, obtaining a high precision to avoid error accumulation of the pipeline structure. To handle grammatical error correction, we design part-of-speech (POS) features and semantic class features to enhance the neural network model, and propose an auxiliary task to predict the POS sequence of the target sentence. Our proposed framework achieves a 42.11 F0.5 score on CGEC dataset without using any synthetic data or data augmentation methods, which outperforms the previous state-of-the-art by a wide margin of 1.30 points. Moreover, our model produces meaningful POS representations that capture different POS words and convey reasonable POS transition rules.