 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Real to Synthetic and Back: Synthesizing Training Data for Multi-Person Scene Understanding
Paper and Code
Jun 03, 2020
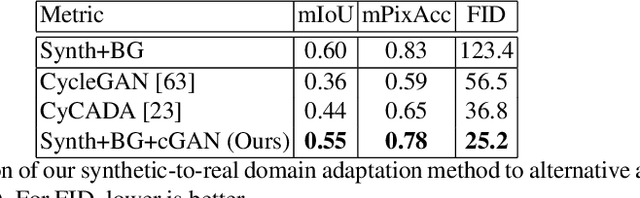


We present a method for synthesizing naturally looking images of multiple people interacting in a specific scenario. These images benefit from the advantages of synthetic data: being fully controllable and fully annotated with any type of standard or custom-defined ground truth. To reduce the synthetic-to-real domain gap, we introduce a pipeline consisting of the following steps: 1) we render scenes in a context modeled after the real world, 2) we train a human parsing model on the synthetic images, 3) we use the model to estimate segmentation maps for real images, 4) we train a conditional generative adversarial network (cGAN) to learn the inverse mapping -- from a segmentation map to a real image, and 5) given new synthetic segmentation maps, we use the cGAN to generate realistic images. An illustration of our pipeline is presented in Figure 2. We use the generated data to train a multi-task model on the challenging tasks of UV mapping and dense depth estimation. We demonstrate the value of the data generation and the trained model, both quantitatively and qualitatively on the CMU Panoptic Dataset.