 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Gating: Improved Convolutional Neural Networks for Speech Enhancement in the Time-Frequency Domain
Paper and Code
Nov 08, 2020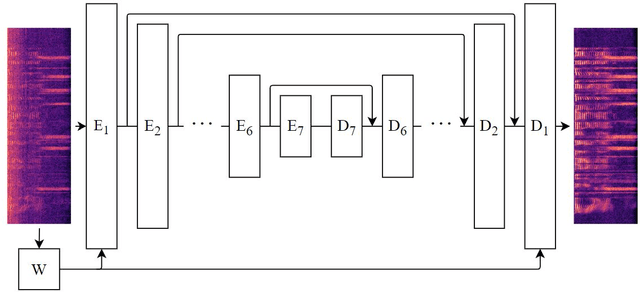



One of the strengths of traditional convolutional neural networks (CNNs) is their inherent translational invariance. However, for the task of speech enhancement in the time-frequency domain, this property cannot be fully exploited due to a lack of invariance in the frequency direction. In this paper we propose to remedy this inefficiency by introducing a method, which we call Frequency Gating, to compute multiplicative weights for the kernels of the CNN in order to make them frequency dependent. Several mechanisms are explored: temporal gating, in which weights are dependent on prior time frames, local gating, whose weights are generated based on a single time frame and the ones adjacent to it, and frequency-wise gating, where each kernel is assigned a weight independent of the input data. Experiments with an autoencoder neural network with skip connections show that both local and frequency-wise gating outperform the baseline and are therefore viable ways to improve CNN-based speech enhancement neural networks. In addition, a loss function based on the extended short-time objective intelligibility score (ESTOI) is introduced, which we show to outperform the standard mean squared error (MSE) loss function.