 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrank Wolfe Meets Metric Entropy
Paper and Code
May 17, 2022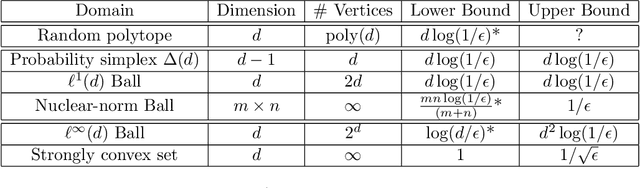

The Frank-Wolfe algorithm has seen a resurgence in popularity due to its ability to efficiently solve constrained optimization problems in machine learning and high-dimensional statistics. As such, there is much interest in establishing when the algorithm may possess a "linear" $O(\log(1/\epsilon))$ dimension-free iteration complexity comparable to projected gradient descent. In this paper, we provide a general technique for establishing domain specific and easy-to-estimate lower bounds for Frank-Wolfe and its variants using the metric entropy of the domain. Most notably, we show that a dimension-free linear upper bound must fail not only in the worst case, but in the \emph{average case}: for a Gaussian or spherical random polytope in $\mathbb{R}^d$ with $\mathrm{poly}(d)$ vertices, Frank-Wolfe requires up to $\tilde\Omega(d)$ iterations to achieve a $O(1/d)$ error bound, with high probability. We also establish this phenomenon for the nuclear norm ball. The link with metric entropy also has interesting positive implications for conditional gradient algorithms in statistics, such as gradient boosting and matching pursuit. In particular, we show that it is possible to extract fast-decaying upper bounds on the excess risk directly from an analysis of the underlying optimization procedure.