 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAKE: Fusional Real-time Automatic Keyword Extraction
Paper and Code
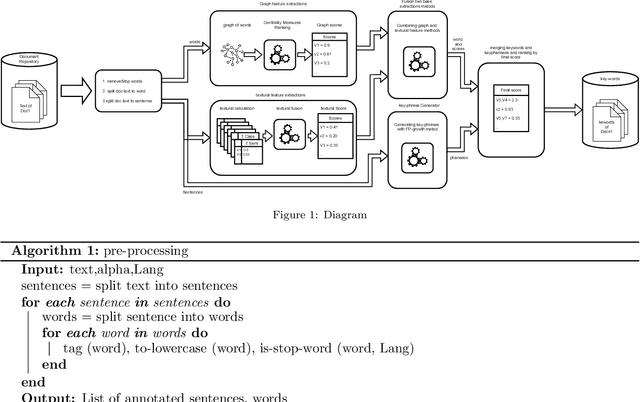



Keyword extraction is called identifying words or phrases that express the main concepts of texts in best. There is a huge amount of texts that are created every day and at all times through electronic infrastructure. So, it is practically impossible for humans to study and manage this volume of documents. However, the need for efficient and effective access to these documents is evident in various purposes. Weblogs, News, and technical notes are almost long texts, while the reader seeks to understand the concepts by topics or keywords to decide for reading the full text. To this aim, we use a combined approach that consists of two models of graph centrality features and textural features. In the following, graph centralities, such as degree, betweenness, eigenvector, and closeness centrality, have been used to optimally combine them to extract the best keyword among the candidate keywords extracted by the proposed method. Also, another approach has been introduced to distinguishing keywords among candidate phrases and considering them as a separate keyword. To evaluate the proposed method, seven datasets named, Semeval2010, SemEval2017, Inspec, fao30, Thesis100, pak2018 and WikiNews have been used, and results reported Precision, Recall, and F- measure.