 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFracBits: Mixed Precision Quantization via Fractional Bit-Widths
Paper and Code
Jul 04, 2020
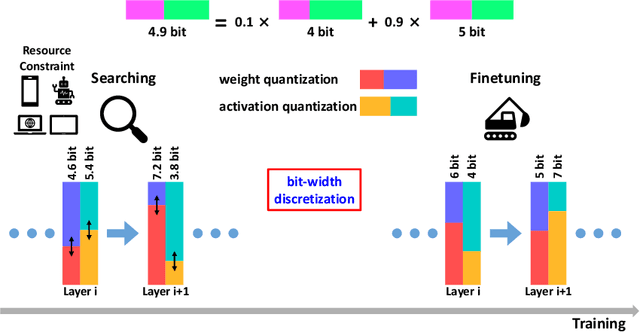
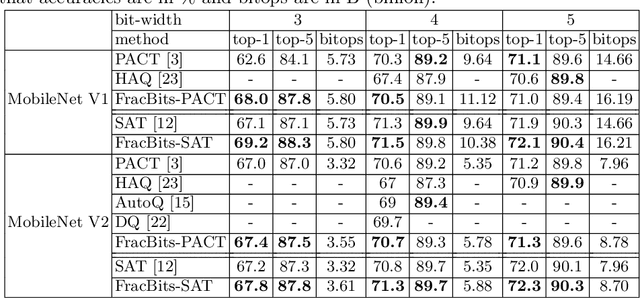
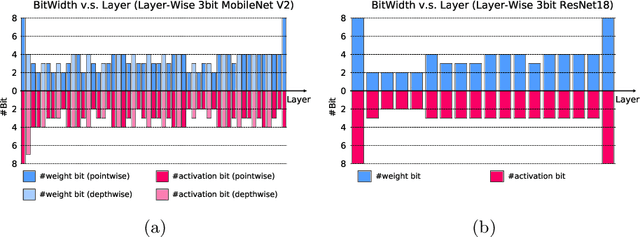
Model quantization helps to reduce model size and latency of deep neural networks. Mixed precision quantization is favorable with customized hardwares supporting arithmetic operations at multiple bit-widths to achieve maximum efficiency. We propose a novel learning-based algorithm to derive mixed precision models end-to-end under target computation constraints and model sizes. During the optimization, the bit-width of each layer / kernel in the model is at a fractional status of two consecutive bit-widths which can be adjusted gradually. With a differentiable regularization term, the resource constraints can be met during the quantization-aware training which results in an optimized mixed precision model. Further, our method can be naturally combined with channel pruning for better computation cost allocation. Our final models achieve comparable or better performance than previous quantization methods with mixed precision on MobilenetV1/V2, ResNet18 under different resource constraints on ImageNet dataset.