 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward Super-Resolution: How Can GANs Learn Hierarchical Generative Models for Real-World Distributions
Paper and Code
Jun 04, 2021


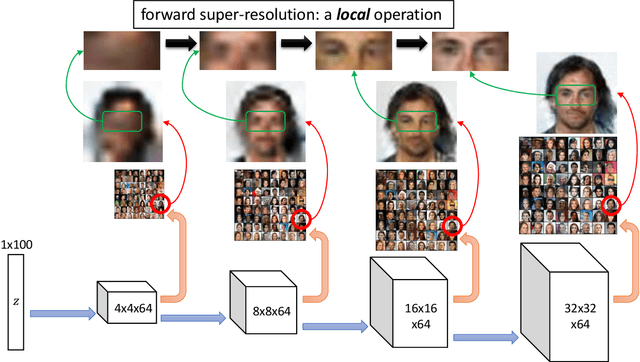
Generative adversarial networks (GANs) are among the most successful models for learning high-complexity, real-world distributions. However, in theory, due to the highly non-convex, non-concave landscape of the minmax training objective, GAN remains one of the least understood deep learning models. In this work, we formally study how GANs can efficiently learn certain hierarchically generated distributions that are close to the distribution of images in practice. We prove that when a distribution has a structure that we refer to as Forward Super-Resolution, then simply training generative adversarial networks using gradient descent ascent (GDA) can indeed learn this distribution efficiently, both in terms of sample and time complexities. We also provide concrete empirical evidence that not only our assumption "forward super-resolution" is very natural in practice, but also the underlying learning mechanisms that we study in this paper (to allow us efficiently train GAN via GDA in theory) simulates the actual learning process of GANs in practice on real-world problems.