 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward-Backward Convolutional Recurrent Neural Networks and Tag-Conditioned Convolutional Neural Networks for Weakly Labeled Semi-supervised Sound Event Detection
Paper and Code
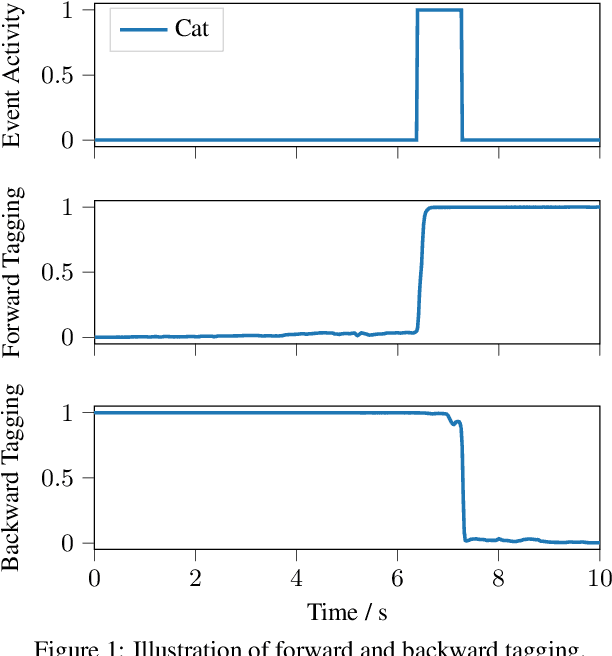

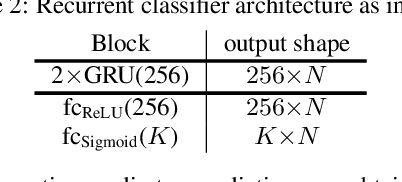
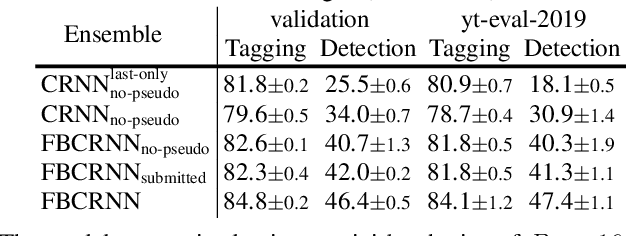
In this paper we present our system for the detection and classification of acoustic scenes and events (DCASE) 2020 Challenge Task 4: Sound event detection and separation in domestic environments. We introduce two new models: the forward-backward convolutional recurrent neural network (FBCRNN) and the tag-conditioned convolutional neural network (CNN). The FBCRNN employs two recurrent neural network (RNN) classifiers sharing the same CNN for preprocessing. With one RNN processing a recording in forward direction and the other in backward direction, the two networks are trained to jointly predict audio tags, i.e., weak labels, at each time step within a recording, given that at each time step they have jointly processed the whole recording. The proposed training encourages the classifiers to tag events as soon as possible. Therefore, after training, the networks can be applied to shorter audio segments of, e.g., 200 ms, allowing sound event detection (SED). Further, we propose a tag-conditioned CNN to complement SED. It is trained to predict strong labels while using (predicted) tags, i.e., weak labels, as additional input. For training pseudo strong labels from a FBCRNN ensemble are used. The presented system scored the fourth and third place in the systems and teams rankings, respectively. Subsequent improvements allow our system to even outperform the challenge baseline and winner systems in average by, respectively, 18.0% and 2.2% event-based F1-score on the validation set. Source code is publicly available at https://github.com/fgnt/pb_sed.