 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForming Trees with Treeformers
Paper and Code

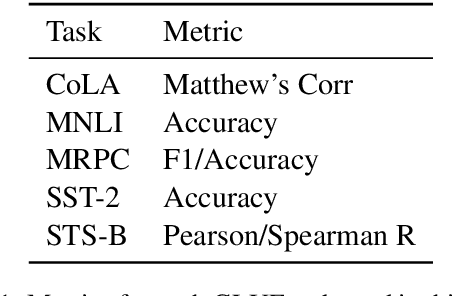
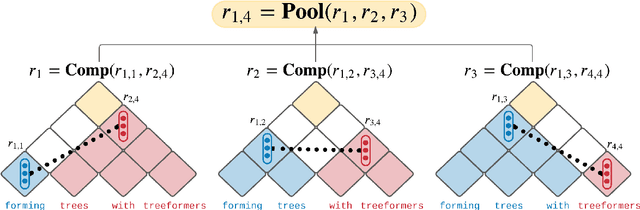
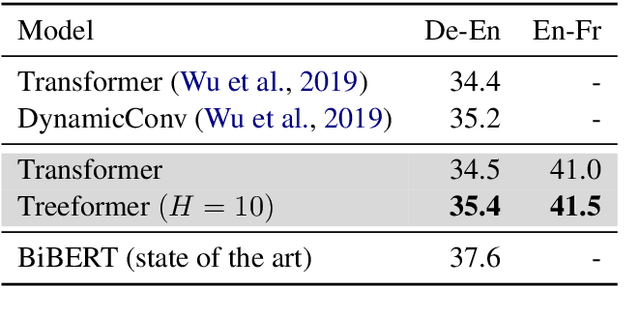
Popular models such as Transformers and LSTMs use tokens as its unit of information. That is, each token is encoded into a vector representation, and those vectors are used directly in a computation. However, humans frequently consider spans of tokens (i.e., phrases) instead of their constituent tokens. In this paper we introduce Treeformer, an architecture inspired by the CKY algorithm and Transformer which learns a composition operator and pooling function in order to construct hierarchical encodings for phrases and sentences. Our extensive experiments demonstrate the benefits of incorporating a hierarchical structure into the Transformer, and show significant improvements compared to a baseline Transformer in machine translation, abstractive summarization, and various natural language understanding tasks.