 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalising the Robustness of Counterfactual Explanations for Neural Networks
Paper and Code

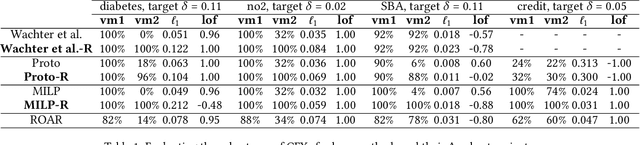


The use of counterfactual explanations (CFXs) is an increasingly popular explanation strategy for machine learning models. However, recent studies have shown that these explanations may not be robust to changes in the underlying model (e.g., following retraining), which raises questions about their reliability in real-world applications. Existing attempts towards solving this problem are heuristic, and the robustness to model changes of the resulting CFXs is evaluated with only a small number of retrained models, failing to provide exhaustive guarantees. To remedy this, we propose the first notion to formally and deterministically assess the robustness (to model changes) of CFXs for neural networks, that we call {\Delta}-robustness. We introduce an abstraction framework based on interval neural networks to verify the {\Delta}-robustness of CFXs against a possibly infinite set of changes to the model parameters, i.e., weights and biases. We then demonstrate the utility of this approach in two distinct ways. First, we analyse the {\Delta}-robustness of a number of CFX generation methods from the literature and show that they unanimously host significant deficiencies in this regard. Second, we demonstrate how embedding {\Delta}-robustness within existing methods can provide CFXs which are provably robust.