 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFor self-supervised learning, Rationality implies generalization, provably
Paper and Code
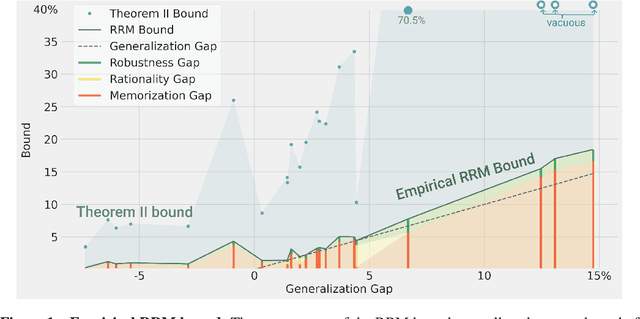

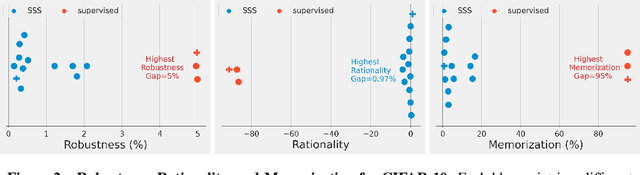
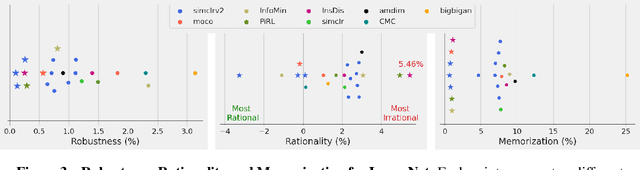
We prove a new upper bound on the generalization gap of classifiers that are obtained by first using self-supervision to learn a representation $r$ of the training data, and then fitting a simple (e.g., linear) classifier $g$ to the labels. Specifically, we show that (under the assumptions described below) the generalization gap of such classifiers tends to zero if $\mathsf{C}(g) \ll n$, where $\mathsf{C}(g)$ is an appropriately-defined measure of the simple classifier $g$'s complexity, and $n$ is the number of training samples. We stress that our bound is independent of the complexity of the representation $r$. We do not make any structural or conditional-independence assumptions on the representation-learning task, which can use the same training dataset that is later used for classification. Rather, we assume that the training procedure satisfies certain natural noise-robustness (adding small amount of label noise causes small degradation in performance) and rationality (getting the wrong label is not better than getting no label at all) conditions that widely hold across many standard architectures. We show that our bound is non-vacuous for many popular representation-learning based classifiers on CIFAR-10 and ImageNet, including SimCLR, AMDIM and MoCo.