 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus On What's Important: Self-Attention Model for Human Pose Estimation
Paper and Code
Sep 22, 2018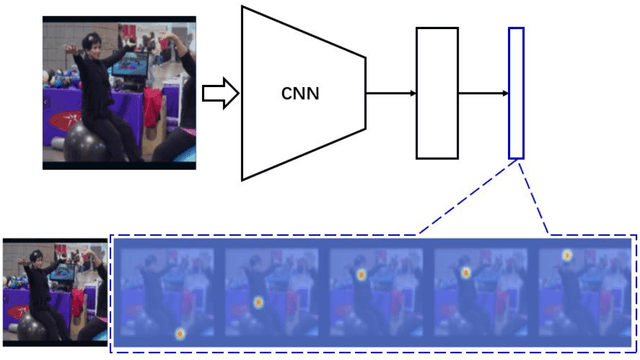
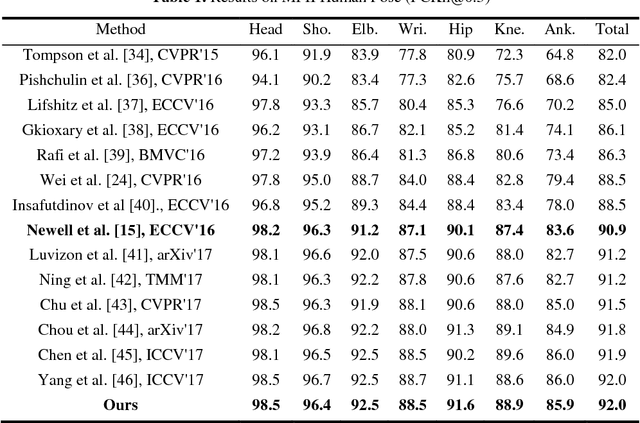
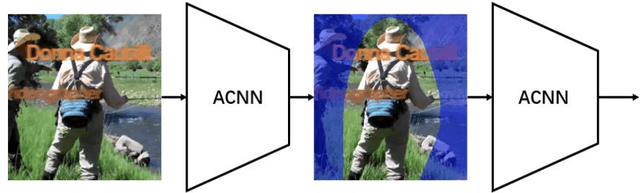
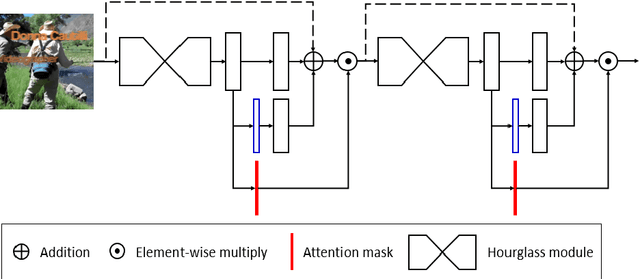
Human pose estimation is an essential yet challenging task in computer vision. One of the reasons for this difficulty is that there are many redundant regions in the images. In this work, we proposed a convolutional network architecture combined with the novel attention model. We named it attention convolutional neural network (ACNN). ACNN learns to focus on specific regions of different input features. It's a multi-stage architecture. Early stages filtrate the "nothing-regions", such as background and redundant body parts. And then, they submit the important regions which contain the joints of the human body to the following stages to get a more accurate result. What's more, it does not require extra manual annotations and self-learning is one of our intentions. We separately trained the network because the attention learning task and the pose estimation task are not independent. State-of-the-art performance is obtained on the MPII benchmarks.