 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-Based Likelihoods for Non-Gaussian Inference
Paper and Code
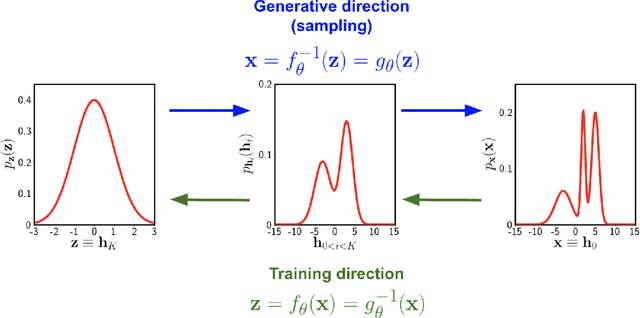


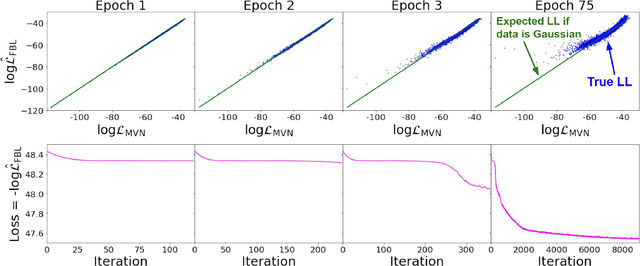
We investigate the use of data-driven likelihoods to bypass a key assumption made in many scientific analyses, which is that the true likelihood of the data is Gaussian. In particular, we suggest using the optimization targets of flow-based generative models, a class of models that can capture complex distributions by transforming a simple base distribution through layers of nonlinearities. We call these flow-based likelihoods (FBL). We analyze the accuracy and precision of the reconstructed likelihoods on mock Gaussian data, and show that simply gauging the quality of samples drawn from the trained model is not a sufficient indicator that the true likelihood has been learned. We nevertheless demonstrate that the likelihood can be reconstructed to a precision equal to that of sampling error due to a finite sample size. We then apply FBLs to mock weak lensing convergence power spectra, a cosmological observable that is significantly non-Gaussian (NG). We find that the FBL captures the NG signatures in the data extremely well, while other commonly-used data-driven likelihoods, such as Gaussian mixture models and independent component analysis, fail to do so. This suggests that works that have found small posterior shifts in NG data with data-driven likelihoods such as these could be underestimating the impact of non-Gaussianity in parameter constraints. By introducing a suite of tests that can capture different levels of NG in the data, we show that the success or failure of traditional data-driven likelihoods can be tied back to the structure of the NG in the data. Unlike other methods, the flexibility of the FBL makes it successful at tackling different types of NG simultaneously. Because of this, and consequently their likely applicability across datasets and domains, we encourage their use for inference when sufficient mock data are available for training.