 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLIER: Few-shot Language Image Models Embedded with Latent Representations
Paper and Code
Oct 10, 2024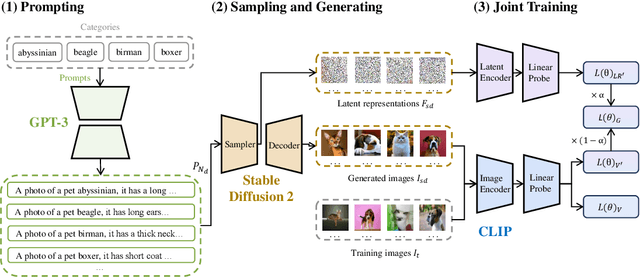

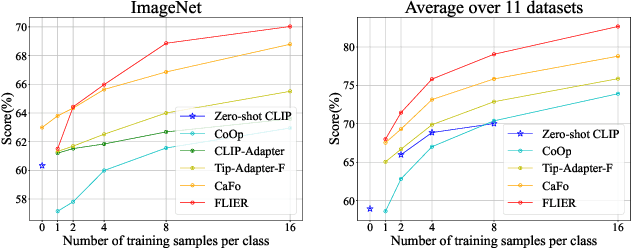
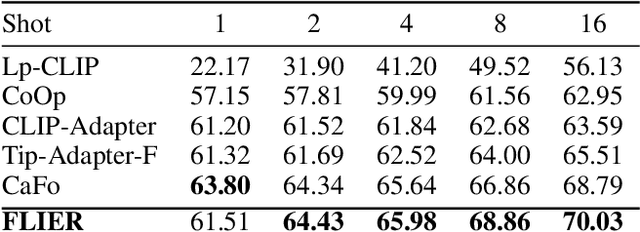
As the boosting development of large vision-language models like Contrastive Language-Image Pre-training (CLIP), many CLIP-like methods have shown impressive abilities on visual recognition, especially in low-data regimes scenes. However, we have noticed that most of these methods are limited to introducing new modifications on text and image encoder. Recently, latent diffusion models (LDMs) have shown good ability on image generation. The potent capabilities of LDMs direct our focus towards the latent representations sampled by UNet. Inspired by the conjecture in CoOp that learned prompts encode meanings beyond the existing vocabulary, we assume that, for deep models, the latent representations are concise and accurate understanding of images, in which high-frequency, imperceptible details are abstracted away. In this paper, we propose a Few-shot Language Image model Embedded with latent Representations (FLIER) for image recognition by introducing a latent encoder jointly trained with CLIP's image encoder, it incorporates pre-trained vision-language knowledge of CLIP and the latent representations from Stable Diffusion. We first generate images and corresponding latent representations via Stable Diffusion with the textual inputs from GPT-3. With latent representations as "models-understandable pixels", we introduce a flexible convolutional neural network with two convolutional layers to be the latent encoder, which is simpler than most encoders in vision-language models. The latent encoder is jointly trained with CLIP's image encoder, transferring pre-trained knowledge to downstream tasks better. Experiments and extensive ablation studies on various visual classification tasks demonstrate that FLIER performs state-of-the-art on 11 datasets for most few-shot classification.