 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Style Image Super-Resolution using Conditional Objective
Paper and Code

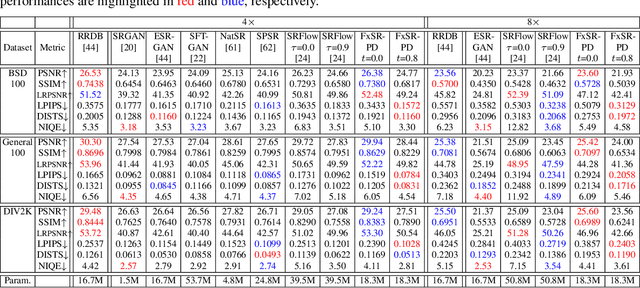
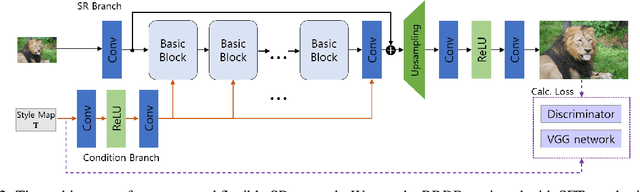
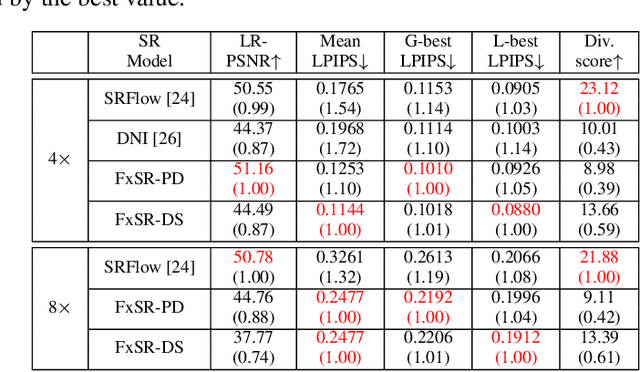
Recent studies have significantly enhanced the performance of single-image super-resolution (SR) using convolutional neural networks (CNNs). While there can be many high-resolution (HR) solutions for a given input, most existing CNN-based methods do not explore alternative solutions during the inference. A typical approach to obtaining alternative SR results is to train multiple SR models with different loss weightings and exploit the combination of these models. Instead of using multiple models, we present a more efficient method to train a single adjustable SR model on various combinations of losses by taking advantage of multi-task learning. Specifically, we optimize an SR model with a conditional objective during training, where the objective is a weighted sum of multiple perceptual losses at different feature levels. The weights vary according to given conditions, and the set of weights is defined as a style controller. Also, we present an architecture appropriate for this training scheme, which is the Residual-in-Residual Dense Block equipped with spatial feature transformation layers. At the inference phase, our trained model can generate locally different outputs conditioned on the style control map. Extensive experiments show that the proposed SR model produces various desirable reconstructions without artifacts and yields comparable quantitative performance to state-of-the-art SR methods.