 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFL-Defender: Combating Targeted Attacks in Federated Learning
Paper and Code
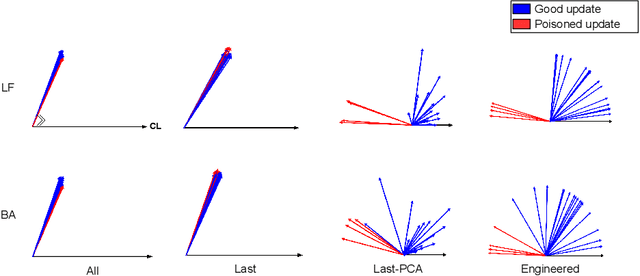
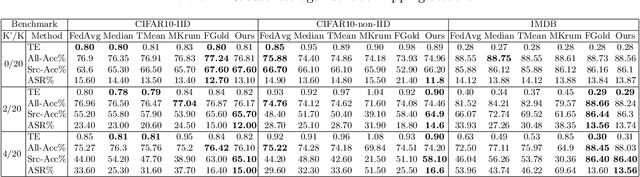
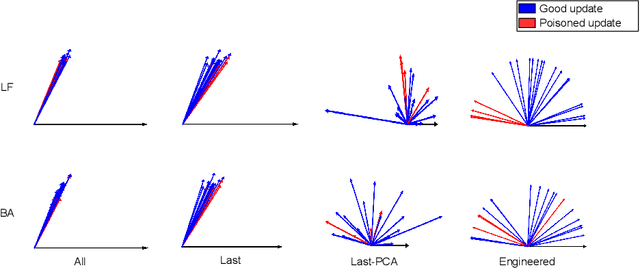
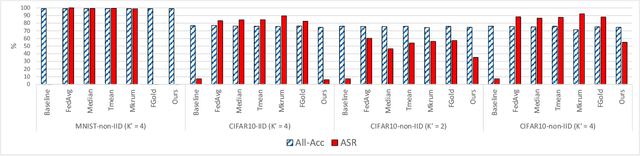
Federated learning (FL) enables learning a global machine learning model from local data distributed among a set of participating workers. This makes it possible i) to train more accurate models due to learning from rich joint training data, and ii) to improve privacy by not sharing the workers' local private data with others. However, the distributed nature of FL makes it vulnerable to targeted poisoning attacks that negatively impact the integrity of the learned model while, unfortunately, being difficult to detect. Existing defenses against those attacks are limited by assumptions on the workers' data distribution, may degrade the global model performance on the main task and/or are ill-suited to high-dimensional models. In this paper, we analyze targeted attacks against FL and find that the neurons in the last layer of a deep learning (DL) model that are related to the attacks exhibit a different behavior from the unrelated neurons, making the last-layer gradients valuable features for attack detection. Accordingly, we propose \textit{FL-Defender} as a method to combat FL targeted attacks. It consists of i) engineering more robust discriminative features by calculating the worker-wise angle similarity for the workers' last-layer gradients, ii) compressing the resulting similarity vectors using PCA to reduce redundant information, and iii) re-weighting the workers' updates based on their deviation from the centroid of the compressed similarity vectors. Experiments on three data sets with different DL model sizes and data distributions show the effectiveness of our method at defending against label-flipping and backdoor attacks. Compared to several state-of-the-art defenses, FL-Defender achieves the lowest attack success rates, maintains the performance of the global model on the main task and causes minimal computational overhead on the server.