 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFitted Learning: Models with Awareness of their Limits
Paper and Code
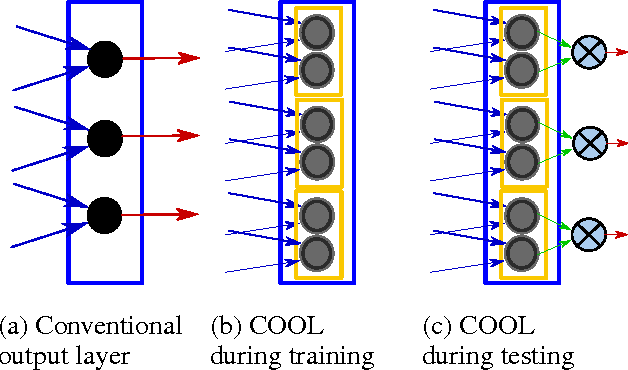
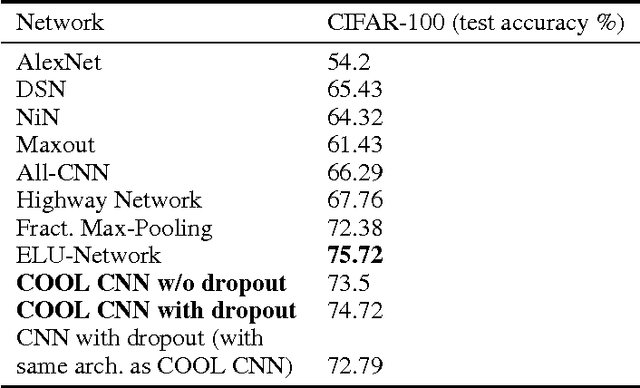
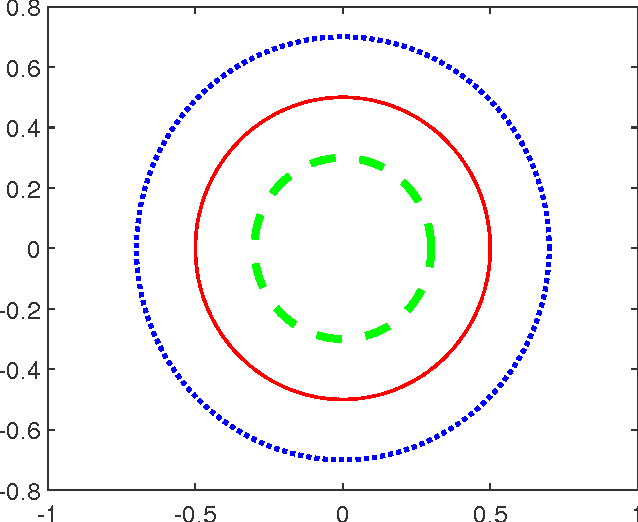
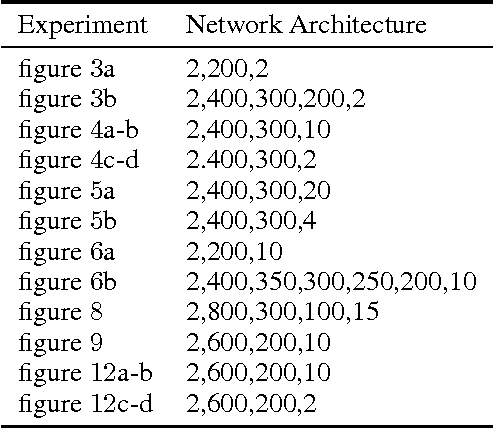
Though deep learning has pushed the boundaries of classification forward, in recent years hints of the limits of standard classification have begun to emerge. Problems such as fooling, adding new classes over time, and the need to retrain learning models only for small changes to the original problem all point to a potential shortcoming in the classic classification regime, where a comprehensive a priori knowledge of the possible classes or concepts is critical. Without such knowledge, classifiers misjudge the limits of their knowledge and overgeneralization therefore becomes a serious obstacle to consistent performance. In response to these challenges, this paper extends the classic regime by reframing classification instead with the assumption that concepts present in the training set are only a sample of the hypothetical final set of concepts. To bring learning models into this new paradigm, a novel elaboration of standard architectures called the competitive overcomplete output layer (COOL) neural network is introduced. Experiments demonstrate the effectiveness of COOL by applying it to fooling, separable concept learning, one-class neural networks, and standard classification benchmarks. The results suggest that, unlike conventional classifiers, the amount of generalization in COOL networks can be tuned to match the problem.