 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIT: Far-reaching Interleaved Transformers
Paper and Code
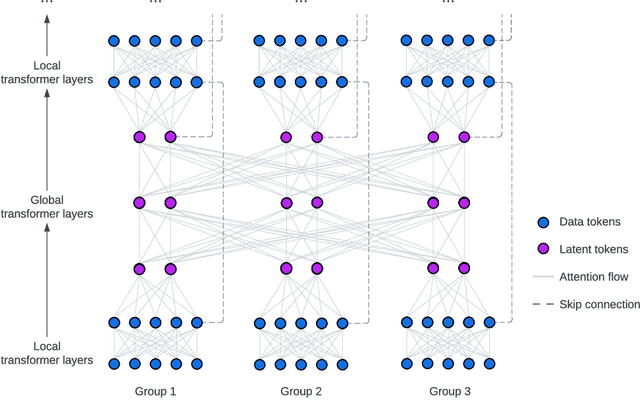
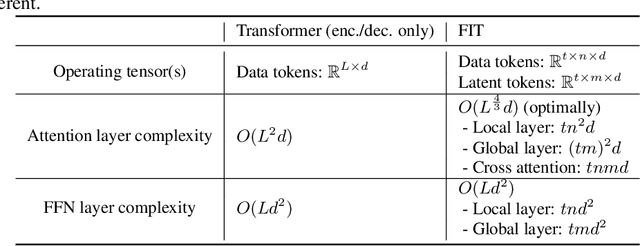
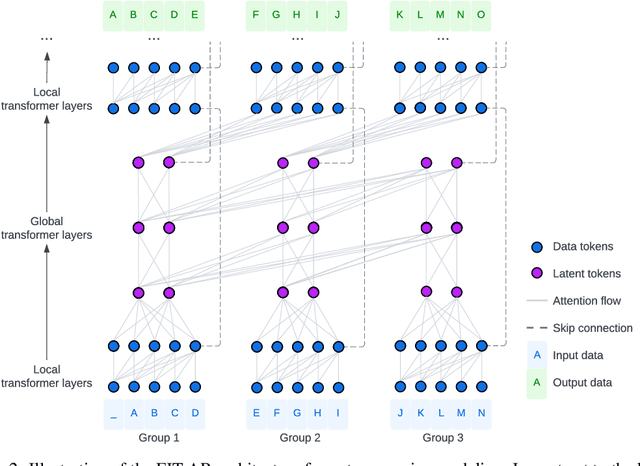
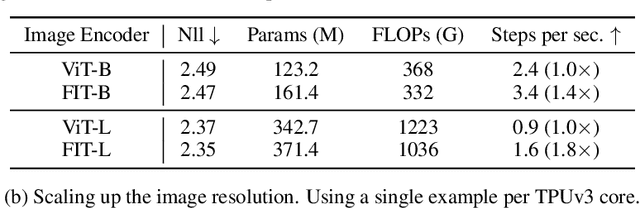
We present FIT: a transformer-based architecture with efficient self-attention and adaptive computation. Unlike original transformers, which operate on a single sequence of data tokens, we divide the data tokens into groups, with each group being a shorter sequence of tokens. We employ two types of transformer layers: local layers operate on data tokens within each group, while global layers operate on a smaller set of introduced latent tokens. These layers, comprising the same set of self-attention and feed-forward layers as standard transformers, are interleaved, and cross-attention is used to facilitate information exchange between data and latent tokens within the same group. The attention complexity is $O(n^2)$ locally within each group of size $n$, but can reach $O(L^{{4}/{3}})$ globally for sequence length of $L$. The efficiency can be further enhanced by relying more on global layers that perform adaptive computation using a smaller set of latent tokens. FIT is a versatile architecture and can function as an encoder, diffusion decoder, or autoregressive decoder. We provide initial evidence demonstrating its effectiveness in high-resolution image understanding and generation tasks. Notably, FIT exhibits potential in performing end-to-end training on gigabit-scale data, such as 6400$\times$6400 images, or 160K tokens (after patch tokenization), within a memory capacity of 16GB, without requiring specific optimizations or model parallelism.