 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinGAN: Generative Adversarial Network for Analytical Customer Relationship Management in Banking and Insurance
Paper and Code
Jan 27, 2022
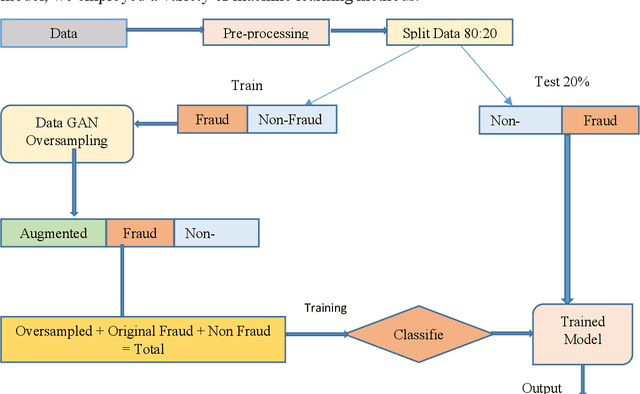

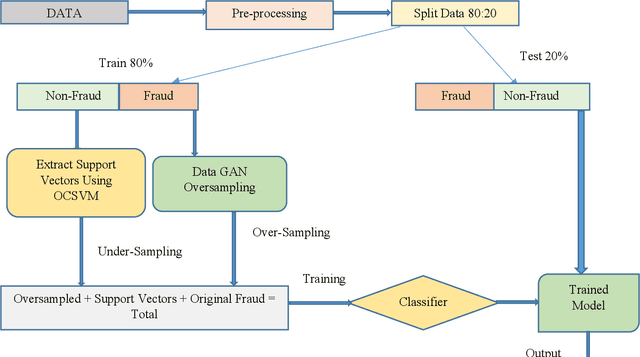
Churn prediction in credit cards, fraud detection in insurance, and loan default prediction are important analytical customer relationship management (ACRM) problems. Since frauds, churns and defaults happen less frequently, the datasets for these problems turn out to be naturally highly unbalanced. Consequently, all supervised machine learning classifiers tend to yield substantial false-positive rates when trained on such unbalanced datasets. We propose two ways of data balancing. In the first, we propose an oversampling method to generate synthetic samples of minority class using Generative Adversarial Network (GAN). We employ Vanilla GAN [1], Wasserstein GAN [2] and CTGAN [3] separately to oversample the minority class samples. In order to assess the efficacy of our proposed approach, we use a host of machine learning classifiers, including Random Forest, Decision Tree, support vector machine (SVM), and Logistic Regression on the data balanced by GANs. In the second method, we introduce a hybrid method to handle data imbalance. In this second way, we utilize the power of undersampling and over-sampling together by augmenting the synthetic minority class data oversampled by GAN with the undersampled majority class data obtained by one-class support vigor machine (OCSVM) [4]. We combine both over-sampled data generated by GAN and the data under-sampled by OCSVM [4] and pass the resultant data to classifiers. When we compared our results to those of Farquad et al. [5], Sundarkumar, Ravi, and Siddeshwar [6], our proposed methods outperform the previous results in terms of the area under the ROC curve (AUC) on all datasets.