 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Recognition in the Wild: A Multi-Task Domain Adaptation Approach
Paper and Code

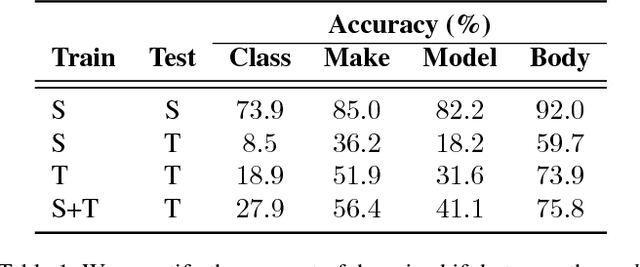
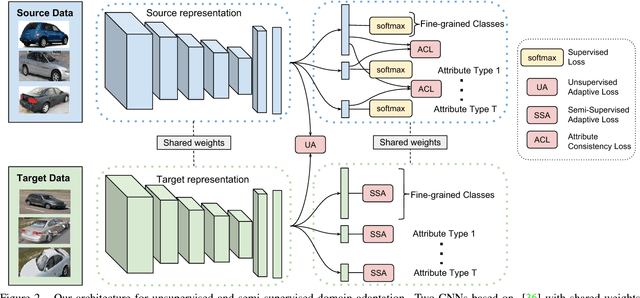
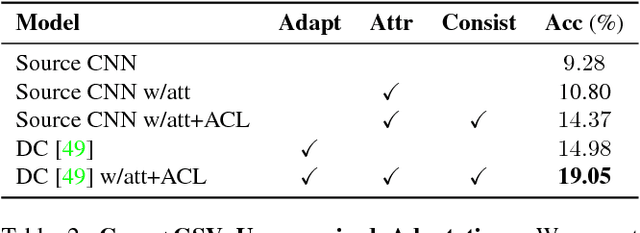
While fine-grained object recognition is an important problem in computer vision, current models are unlikely to accurately classify objects in the wild. These fully supervised models need additional annotated images to classify objects in every new scenario, a task that is infeasible. However, sources such as e-commerce websites and field guides provide annotated images for many classes. In this work, we study fine-grained domain adaptation as a step towards overcoming the dataset shift between easily acquired annotated images and the real world. Adaptation has not been studied in the fine-grained setting where annotations such as attributes could be used to increase performance. Our work uses an attribute based multi-task adaptation loss to increase accuracy from a baseline of 4.1% to 19.1% in the semi-supervised adaptation case. Prior do- main adaptation works have been benchmarked on small datasets such as [46] with a total of 795 images for some domains, or simplistic datasets such as [41] consisting of digits. We perform experiments on a subset of a new challenging fine-grained dataset consisting of 1,095,021 images of 2, 657 car categories drawn from e-commerce web- sites and Google Street View.