 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Early Frequency Attention for Deep Speaker Recognition
Paper and Code
Jul 20, 2022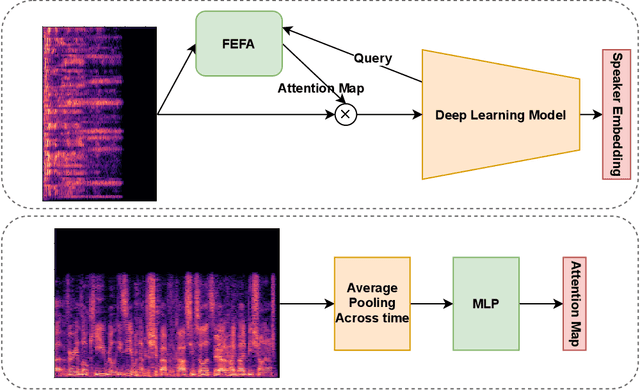

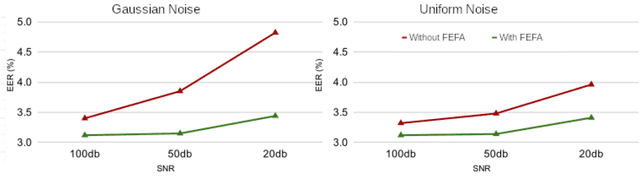
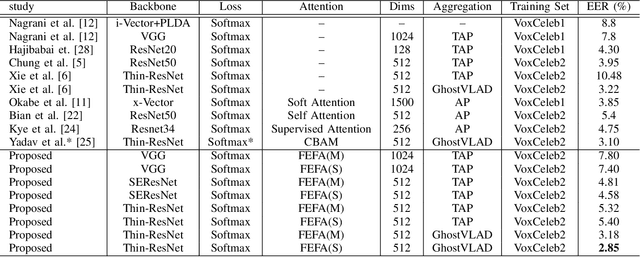
Attention mechanisms have emerged as important tools that boost the performance of deep models by allowing them to focus on key parts of learned embeddings. However, current attention mechanisms used in speaker recognition tasks fail to consider fine-grained information items such as frequency bins in input spectral representations used by the deep networks. To address this issue, we propose the novel Fine-grained Early Frequency Attention (FEFA) for speaker recognition in-the-wild. Once integrated into a deep neural network, our proposed mechanism works by obtaining queries from early layers of the network and generating learnable weights to attend to information items as small as the frequency bins in the input spectral representations. To evaluate the performance of FEFA, we use several well-known deep models as backbone networks and integrate our attention module in their pipelines. The overall performance of these networks (with and without FEFA) are evaluated on the VoxCeleb1 dataset, where we observe considerable improvements when FEFA is used.