 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Stable Groups of Cross-Correlated Features in Multi-View data
Paper and Code
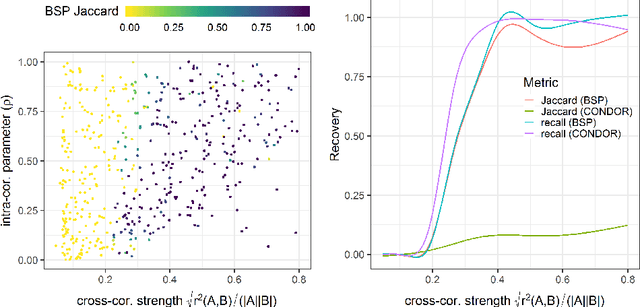

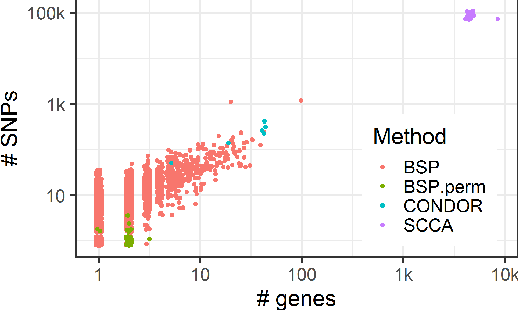
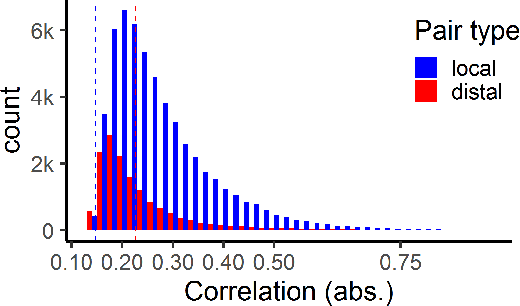
Multi-view data, in which data of different types are obtained from a common set of samples, is now common in many scientific problems. An important problem in the analysis of multi-view data is identifying interactions between groups of features from different data types. A bimodule is a pair $(A,B)$ of feature sets from two different data types such that the aggregate cross-correlation between the features in $A$ and those in $B$ is large. A bimodule $(A,B)$ is stable if $A$ coincides with the set of features having significant aggregate correlation with the features in $B$, and vice-versa. At the population level, stable bimodules correspond to connected components of the cross-correlation network, which is the bipartite graph whose edges are pairs of features with non-zero cross-correlations. We develop an iterative, testing-based procedure, called BSP, to identify stable bimodules in two moderate- to high-dimensional data sets. BSP relies on permutation-based p-values for sums of squared cross-correlations. We efficiently approximate the p-values using tail probabilities of gamma distributions that are fit using analytical estimates of the permutation moments of the test statistic. Our moment estimates depend on the eigenvalues of the intra-correlation matrices of $A$ and $B$ and as a result, the significance of observed cross-correlations accounts for the correlations within each data type. We carry out a thorough simulation study to assess the performance of BSP, and present an extended application of BSP to the problem of expression quantitative trait loci (eQTL) analysis using recent data from the GTEx project. In addition, we apply BSP to climatology data in order to identify regions in North America where annual temperature variation affects precipitation.