 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Meaningful Distributions of ML Black-boxes under Forensic Investigation
Paper and Code
May 10, 2023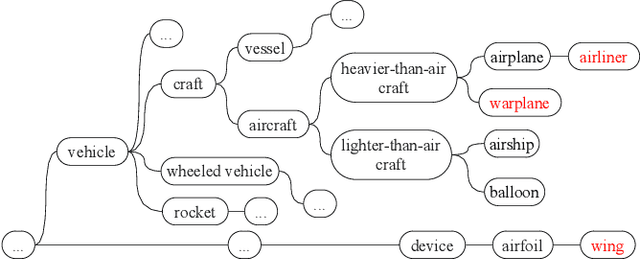
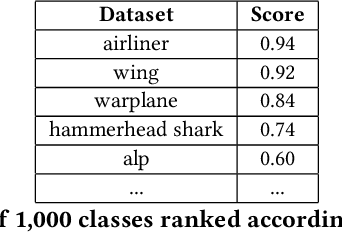
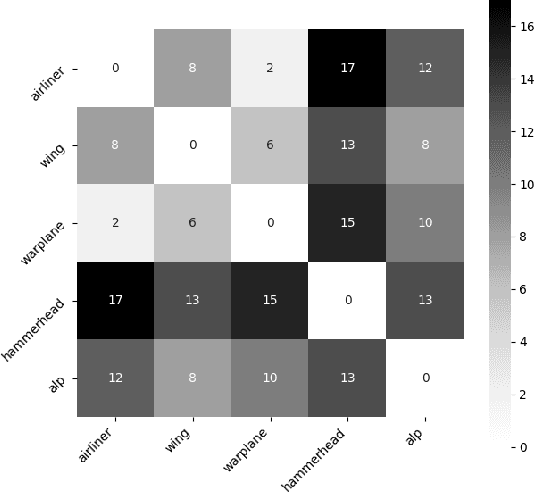
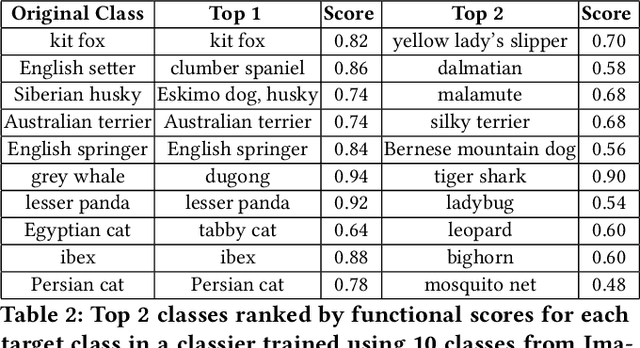
Given a poorly documented neural network model, we take the perspective of a forensic investigator who wants to find out the model's data domain (e.g. whether on face images or traffic signs). Although existing methods such as membership inference and model inversion can be used to uncover some information about an unknown model, they still require knowledge of the data domain to start with. In this paper, we propose solving this problem by leveraging on comprehensive corpus such as ImageNet to select a meaningful distribution that is close to the original training distribution and leads to high performance in follow-up investigations. The corpus comprises two components, a large dataset of samples and meta information such as hierarchical structure and textual information on the samples. Our goal is to select a set of samples from the corpus for the given model. The core of our method is an objective function that considers two criteria on the selected samples: the model functional properties (derived from the dataset), and semantics (derived from the metadata). We also give an algorithm to efficiently search the large space of all possible subsets w.r.t. the objective function. Experimentation results show that the proposed method is effective. For example, cloning a given model (originally trained with CIFAR-10) by using Caltech 101 can achieve 45.5% accuracy. By using datasets selected by our method, the accuracy is improved to 72.0%.