 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinBERT-MRC: financial named entity recognition using BERT under the machine reading comprehension paradigm
Paper and Code
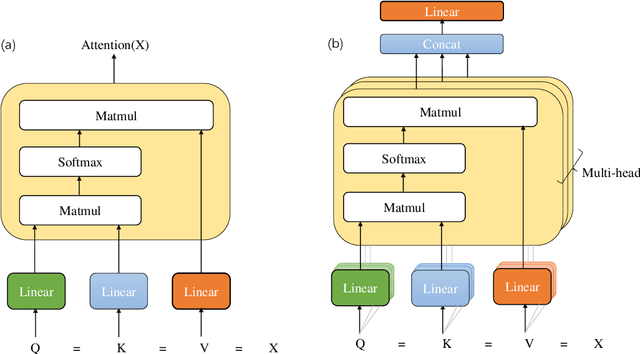
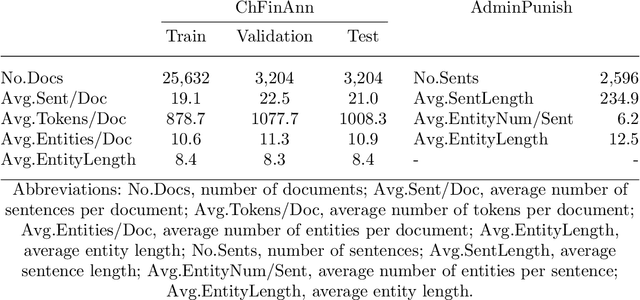
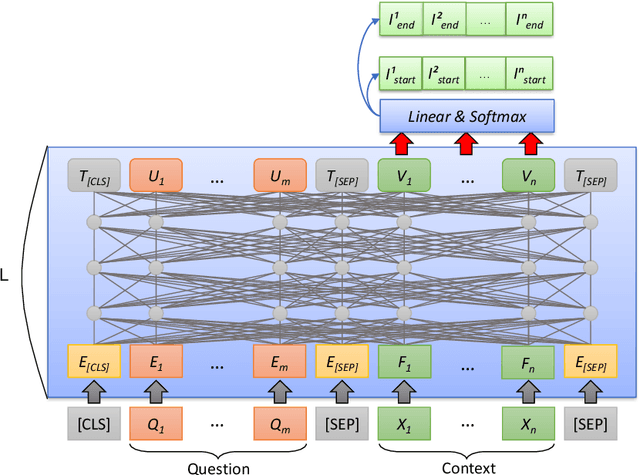
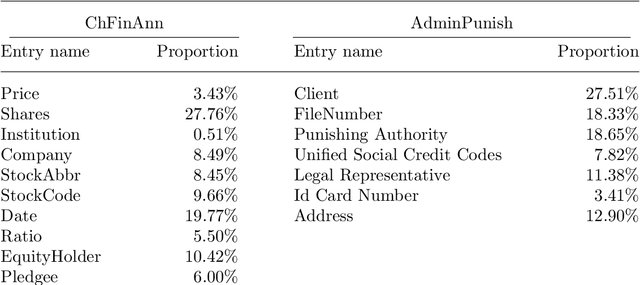
Financial named entity recognition (FinNER) from literature is a challenging task in the field of financial text information extraction, which aims to extract a large amount of financial knowledge from unstructured texts. It is widely accepted to use sequence tagging frameworks to implement FinNER tasks. However, such sequence tagging models cannot fully take advantage of the semantic information in the texts. Instead, we formulate the FinNER task as a machine reading comprehension (MRC) problem and propose a new model termed FinBERT-MRC. This formulation introduces significant prior information by utilizing well-designed queries, and extracts start index and end index of target entities without decoding modules such as conditional random fields (CRF). We conduct experiments on a publicly available Chinese financial dataset ChFinAnn and a real-word bussiness dataset AdminPunish. FinBERT-MRC model achieves average F1 scores of 92.78% and 96.80% on the two datasets, respectively, with average F1 gains +3.94% and +0.89% over some sequence tagging models including BiLSTM-CRF, BERT-Tagger, and BERT-CRF. The source code is available at https://github.com/zyz0000/FinBERT-MRC.