Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial Time Series Data Processing for Machine Learning
Paper and Code
Jul 03, 2019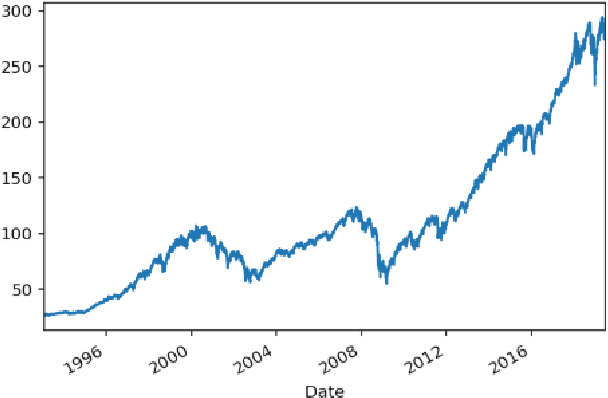

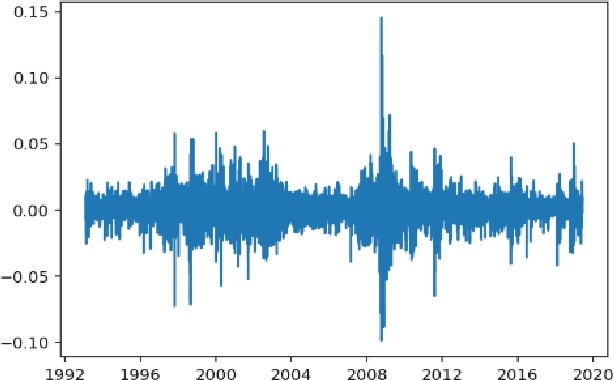

This article studies the financial time series data processing for machine learning. It introduces the most frequent scaling methods, then compares the resulting stationarity and preservation of useful information for trend forecasting. It proposes an empirical test based on the capability to learn simple data relationship with simple models. It also speaks about the data split method specific to time series, avoiding unwanted overfitting and proposes various labelling for classification and regression.
View paper on