 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Image Classification via Contrastive Self-Supervised Learning
Paper and Code
Aug 23, 2020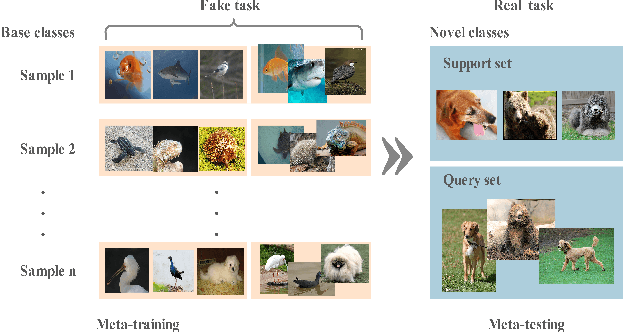
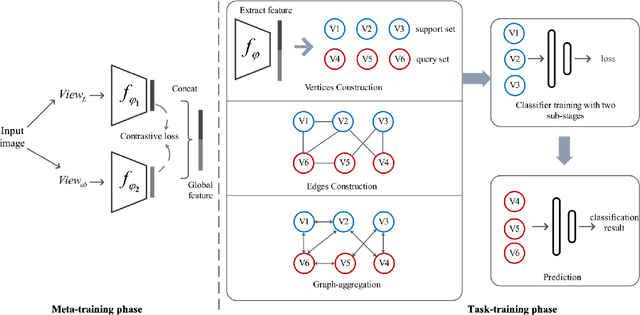
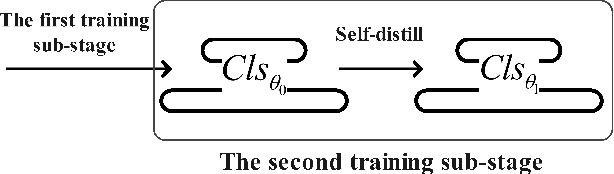
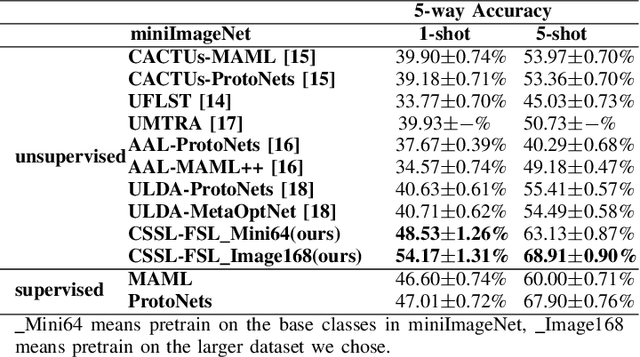
Most previous few-shot learning algorithms are based on meta-training with fake few-shot tasks as training samples, where large labeled base classes are required. The trained model is also limited by the type of tasks. In this paper we propose a new paradigm of unsupervised few-shot learning to repair the deficiencies. We solve the few-shot tasks in two phases: meta-training a transferable feature extractor via contrastive self-supervised learning and training a classifier using graph aggregation, self-distillation and manifold augmentation. Once meta-trained, the model can be used in any type of tasks with a task-dependent classifier training. Our method achieves state of-the-art performance in a variety of established few-shot tasks on the standard few-shot visual classification datasets, with an 8- 28% increase compared to the available unsupervised few-shot learning methods.