 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Image Classification Along Sparse Graphs
Paper and Code
Dec 07, 2021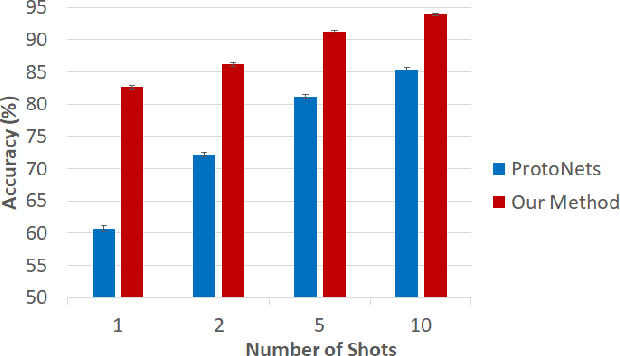
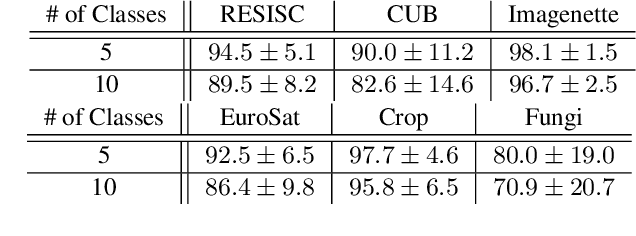
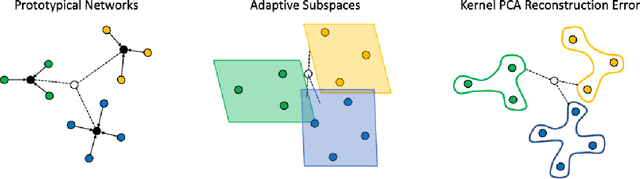
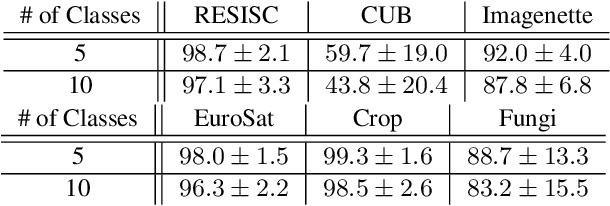
Few-shot learning remains a challenging problem, with unsatisfactory 1-shot accuracies for most real-world data. Here, we present a different perspective for data distributions in the feature space of a deep network and show how to exploit it for few-shot learning. First, we observe that nearest neighbors in the feature space are with high probability members of the same class while generally two random points from one class are not much closer to each other than points from different classes. This observation suggests that classes in feature space form sparse, loosely connected graphs instead of dense clusters. To exploit this property, we propose using a small amount of label propagation into the unlabeled space and then using a kernel PCA reconstruction error as decision boundary for the feature-space data distribution of each class. Using this method, which we call "K-Prop," we demonstrate largely improved few-shot learning performances (e.g., 83% accuracy for 1-shot 5-way classification on the RESISC45 satellite-images dataset) for datasets for which a backbone network can be trained with high within-class nearest-neighbor probabilities. We demonstrate this relationship using six different datasets.