Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedOS: using open-set learning to stabilize training in federated learning
Paper and Code

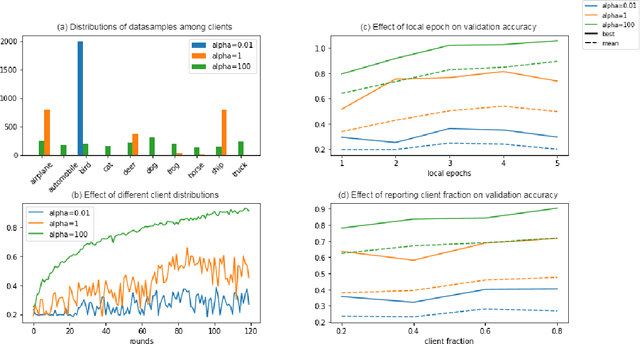
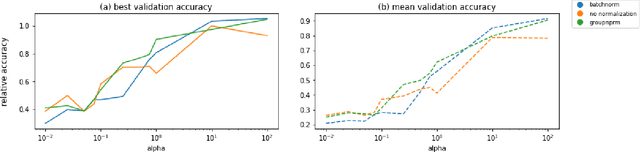
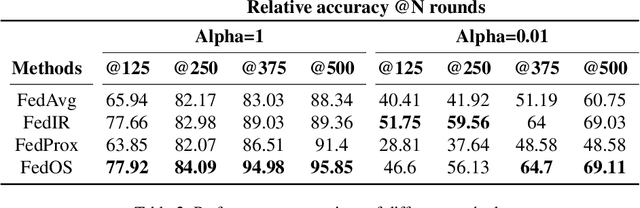
Federated Learning is a recent approach to train statistical models on distributed datasets without violating privacy constraints. The data locality principle is preserved by sharing the model instead of the data between clients and the server. This brings many advantages but also poses new challenges. In this report, we explore this new research area and perform several experiments to deepen our understanding of what these challenges are and how different problem settings affect the performance of the final model. Finally, we present a novel approach to one of these challenges and compare it to other methods found in literature.
* Project report for the course of Advance Machine Learning. year
2021-22, Polytechnic of Turin
View paper on