 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Semi-Supervised Domain Adaptation via Knowledge Transfer
Paper and Code
Jul 25, 2022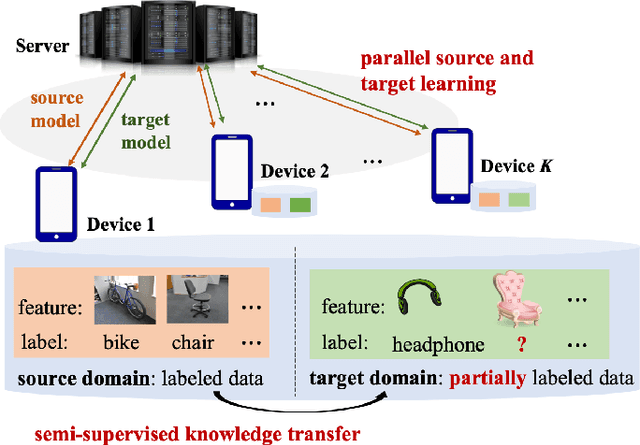
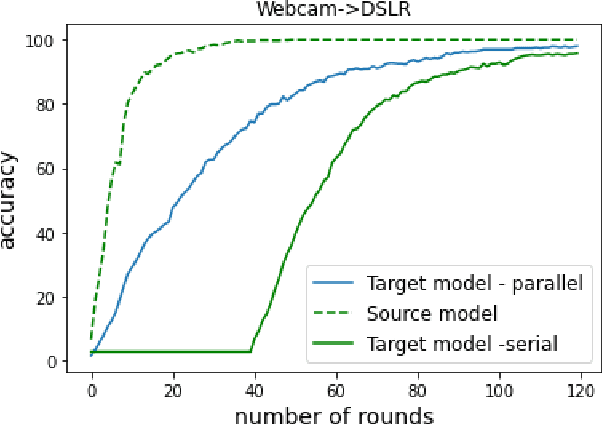
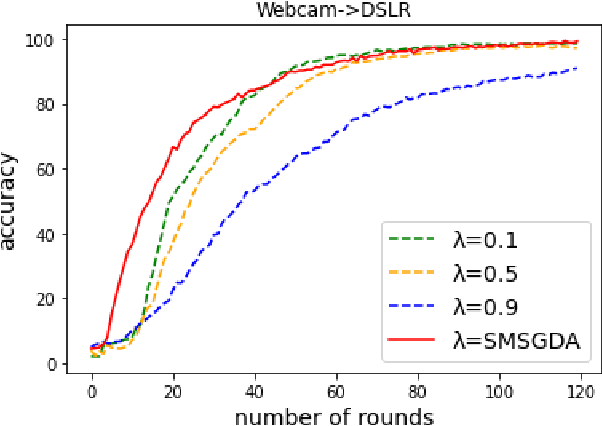
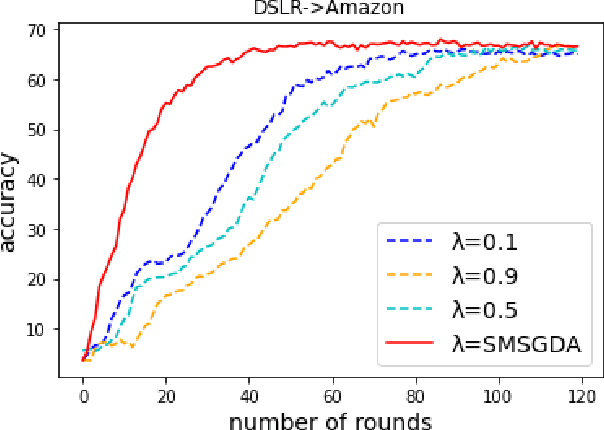
Given the rapidly changing machine learning environments and expensive data labeling, semi-supervised domain adaptation (SSDA) is imperative when the labeled data from the source domain is statistically different from the partially labeled data from the target domain. Most prior SSDA research is centrally performed, requiring access to both source and target data. However, data in many fields nowadays is generated by distributed end devices. Due to privacy concerns, the data might be locally stored and cannot be shared, resulting in the ineffectiveness of existing SSDA research. This paper proposes an innovative approach to achieve SSDA over multiple distributed and confidential datasets, named by Federated Semi-Supervised Domain Adaptation (FSSDA). FSSDA integrates SSDA with federated learning based on strategically designed knowledge distillation techniques, whose efficiency is improved by performing source and target training in parallel. Moreover, FSSDA controls the amount of knowledge transferred across domains by properly selecting a key parameter, i.e., the imitation parameter. Further, the proposed FSSDA can be effectively generalized to multi-source domain adaptation scenarios. Extensive experiments are conducted to demonstrate the effectiveness and efficiency of FSSDA design.