 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with a Single Shared Image
Paper and Code
Jun 18, 2024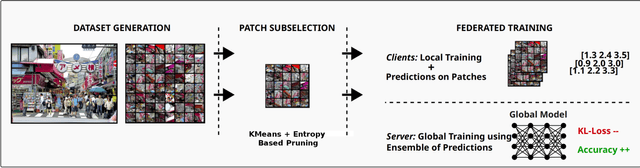

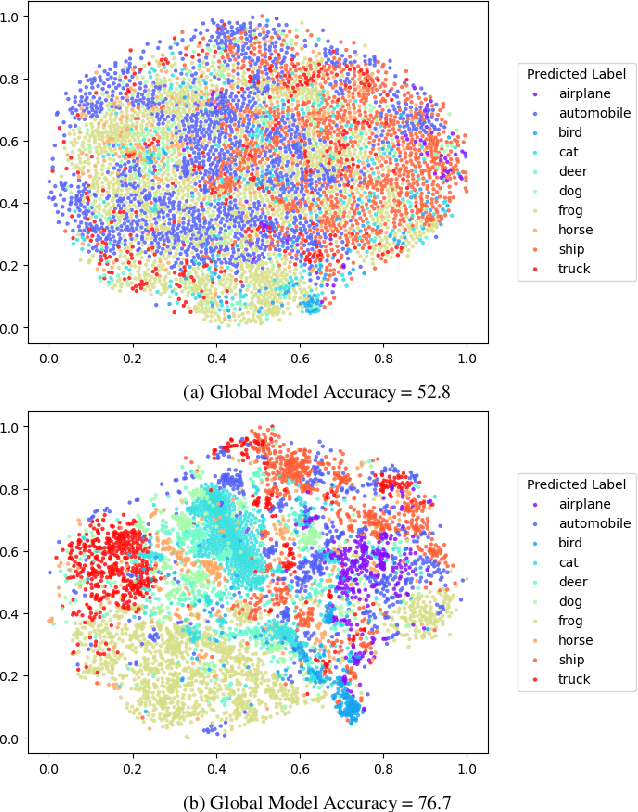
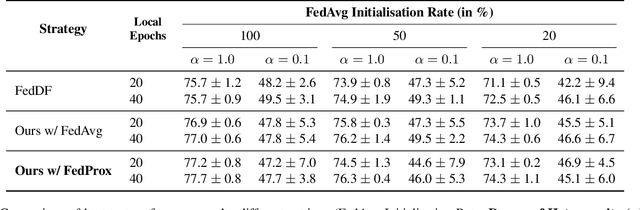
Federated Learning (FL) enables multiple machines to collaboratively train a machine learning model without sharing of private training data. Yet, especially for heterogeneous models, a key bottleneck remains the transfer of knowledge gained from each client model with the server. One popular method, FedDF, uses distillation to tackle this task with the use of a common, shared dataset on which predictions are exchanged. However, in many contexts such a dataset might be difficult to acquire due to privacy and the clients might not allow for storage of a large shared dataset. To this end, in this paper, we introduce a new method that improves this knowledge distillation method to only rely on a single shared image between clients and server. In particular, we propose a novel adaptive dataset pruning algorithm that selects the most informative crops generated from only a single image. With this, we show that federated learning with distillation under a limited shared dataset budget works better by using a single image compared to multiple individual ones. Finally, we extend our approach to allow for training heterogeneous client architectures by incorporating a non-uniform distillation schedule and client-model mirroring on the server side.