 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning over Noisy Channels: Convergence Analysis and Design Examples
Paper and Code
Jan 06, 2021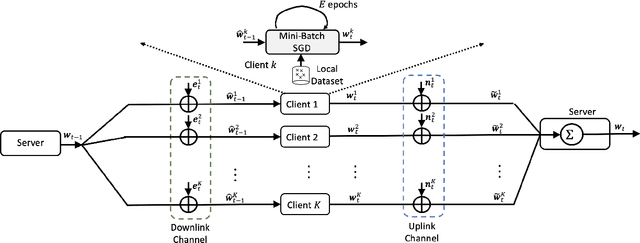


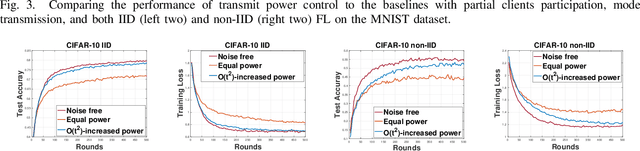
Does Federated Learning (FL) work when both uplink and downlink communications have errors? How much communication noise can FL handle and what is its impact to the learning performance? This work is devoted to answering these practically important questions by explicitly incorporating both uplink and downlink noisy channels in the FL pipeline. We present several novel convergence analyses of FL over simultaneous uplink and downlink noisy communication channels, which encompass full and partial clients participation, direct model and model differential transmissions, and non-independent and identically distributed (IID) local datasets. These analyses characterize the sufficient conditions for FL over noisy channels to have the same convergence behavior as the ideal case of no communication error. More specifically, in order to maintain the O(1/T) convergence rate of FedAvg with perfect communications, the uplink and downlink signal-to-noise ratio (SNR) for direct model transmissions should be controlled such that they scale as O(t^2) where t is the index of communication rounds, but can stay constant for model differential transmissions. The key insight of these theoretical results is a "flying under the radar" principle - stochastic gradient descent (SGD) is an inherent noisy process and uplink/downlink communication noises can be tolerated as long as they do not dominate the time-varying SGD noise. We exemplify these theoretical findings with two widely adopted communication techniques - transmit power control and diversity combining - and further validating their performance advantages over the standard methods via extensive numerical experiments using several real-world FL tasks.