 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning in ASR: Not as Easy as You Think
Paper and Code


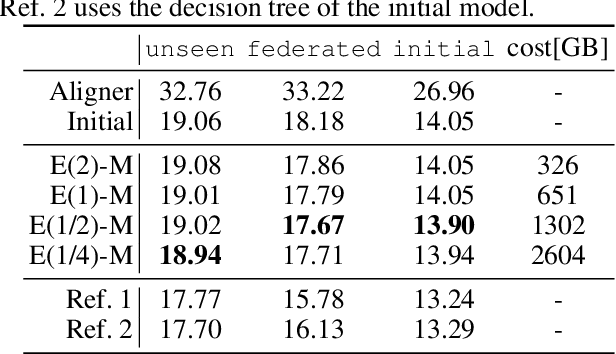
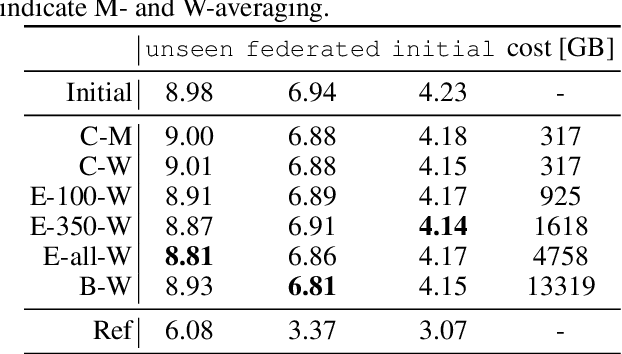
With the growing availability of smart devices and cloud services, personal speech assistance systems are increasingly used on a daily basis. Most devices redirect the voice recordings to a central server, which uses them for upgrading the recognizer model. This leads to major privacy concerns, since private data could be misused by the server or third parties. Federated learning is a decentralized optimization strategy that has been proposed to address such concerns. Utilizing this approach, private data is used for on-device training. Afterwards, updated model parameters are sent to the server to improve the global model, which is redistributed to the clients. In this work, we implement federated learning for speech recognition in a hybrid and an end-to-end model. We discuss the outcomes of these systems, which both show great similarities and only small improvements, pointing to a need for a deeper understanding of federated learning for speech recognition.