 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Feature Selection for Cyber-Physical Systems of Systems
Paper and Code
Sep 23, 2021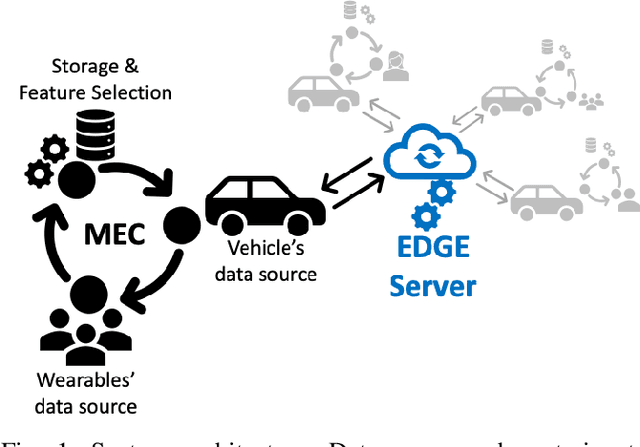



Autonomous systems generate a huge amount of multimodal data that are collected and processed on the Edge, in order to enable AI-based services. The collected datasets are pre-processed in order to extract informative attributes, called features, which are used to feed AI algorithms. Due to the limited computational and communication resources of some CPS, like autonomous vehicles, selecting the subset of relevant features from a dataset is of the utmost importance, in order to improve the result achieved by learning methods and to reduce computation and communication costs. Precisely, feature selection is the candidate approach, which assumes that data contain a certain number of redundant or irrelevant attributes that can be eliminated. The quality of our methods is confirmed by the promising results achieved on two different data sets. In this work, we propose, for the first time, a federated feature selection method suitable for being executed in a distributed manner. Precisely, our results show that a fleet of autonomous vehicles finds a consensus on the optimal set of features that they exploit to reduce data transmission up to 99% with negligible information loss.