 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection integrated Deep Learning for Ultrahigh Dimensional and Highly Correlated Feature Space
Paper and Code
Sep 18, 2022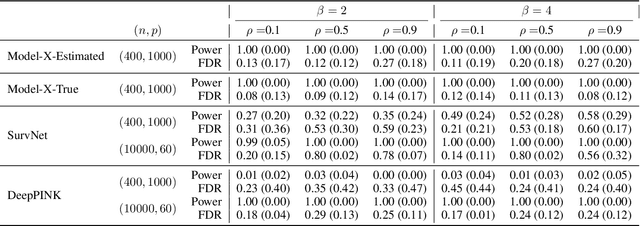
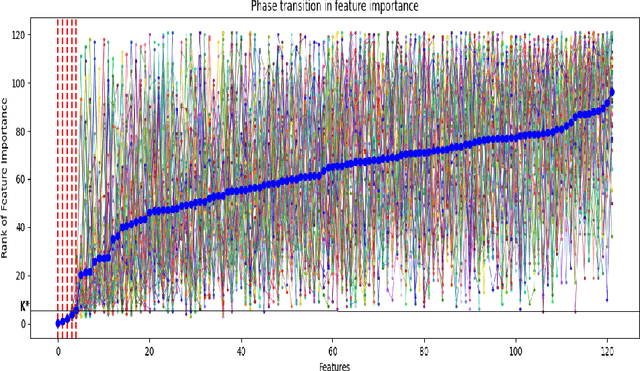
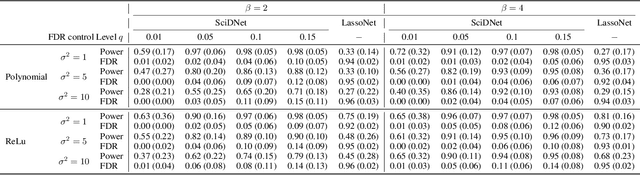

In recent years, deep learning has been a topic of interest in almost all disciplines due to its impressive empirical success in analyzing complex data sets, such as imaging, genetics, climate, and medical data. While most of the developments are treated as black-box machines, there is an increasing interest in interpretable, reliable, and robust deep learning models applicable to a broad class of applications. Feature-selected deep learning is proven to be promising in this regard. However, the recent developments do not address the situations of ultra-high dimensional and highly correlated feature selection in addition to the high noise level. In this article, we propose a novel screening and cleaning strategy with the aid of deep learning for the cluster-level discovery of highly correlated predictors with a controlled error rate. A thorough empirical evaluation over a wide range of simulated scenarios demonstrates the effectiveness of the proposed method by achieving high power while having a minimal number of false discoveries. Furthermore, we implemented the algorithm in the riboflavin (vitamin $B_2$) production dataset in the context of understanding the possible genetic association with riboflavin production. The gain of the proposed methodology is illustrated by achieving lower prediction error compared to other state-of-the-art methods.