 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastTalker: Jointly Generating Speech and Conversational Gestures from Text
Paper and Code
Sep 24, 2024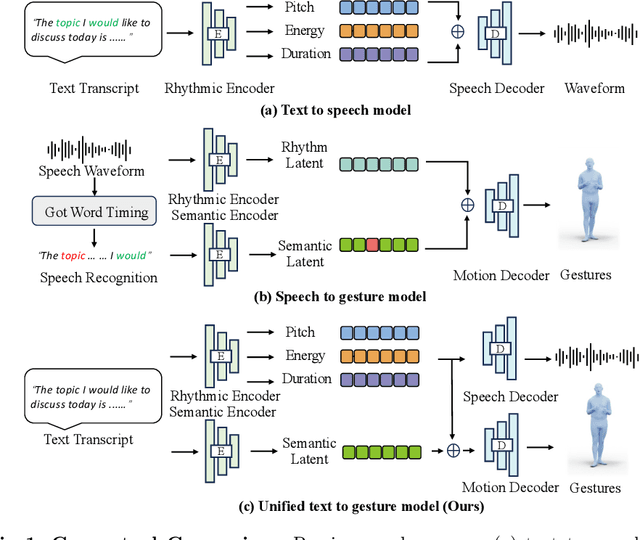



Generating 3D human gestures and speech from a text script is critical for creating realistic talking avatars. One solution is to leverage separate pipelines for text-to-speech (TTS) and speech-to-gesture (STG), but this approach suffers from poor alignment of speech and gestures and slow inference times. In this paper, we introduce FastTalker, an efficient and effective framework that simultaneously generates high-quality speech audio and 3D human gestures at high inference speeds. Our key insight is reusing the intermediate features from speech synthesis for gesture generation, as these features contain more precise rhythmic information than features re-extracted from generated speech. Specifically, 1) we propose an end-to-end framework that concurrently generates speech waveforms and full-body gestures, using intermediate speech features such as pitch, onset, energy, and duration directly for gesture decoding; 2) we redesign the causal network architecture to eliminate dependencies on future inputs for real applications; 3) we employ Reinforcement Learning-based Neural Architecture Search (NAS) to enhance both performance and inference speed by optimizing our network architecture. Experimental results on the BEAT2 dataset demonstrate that FastTalker achieves state-of-the-art performance in both speech synthesis and gesture generation, processing speech and gestures in 0.17 seconds per second on an NVIDIA 3090.