 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastS2S-VC: Streaming Non-Autoregressive Sequence-to-Sequence Voice Conversion
Paper and Code
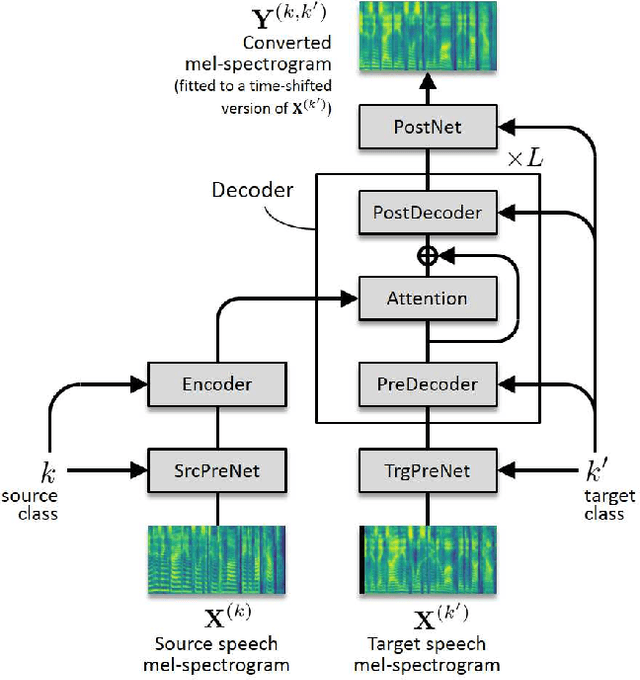
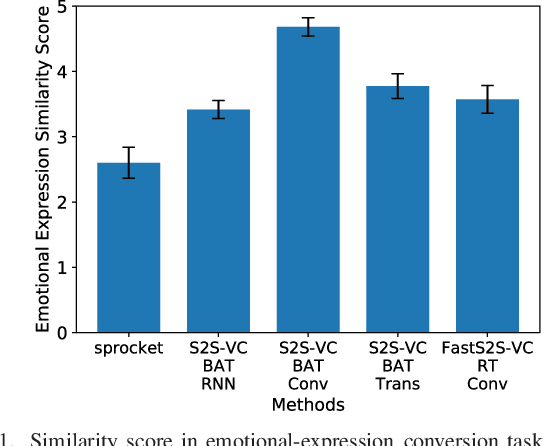
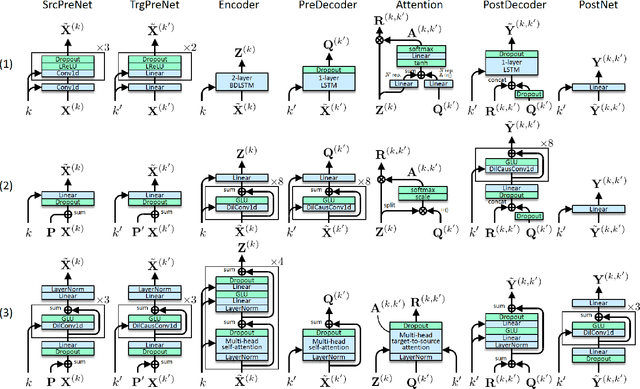
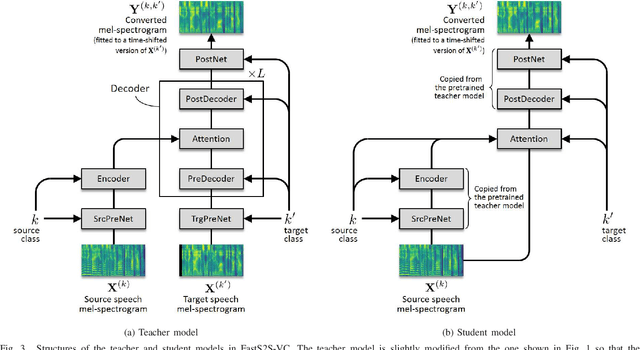
This paper proposes a non-autoregressive extension of our previously proposed sequence-to-sequence (S2S) model-based voice conversion (VC) methods. S2S model-based VC methods have attracted particular attention in recent years for their flexibility in converting not only the voice identity but also the pitch contour and local duration of input speech, thanks to the ability of the encoder-decoder architecture with the attention mechanism. However, one of the obstacles to making these methods work in real-time is the autoregressive (AR) structure. To overcome this obstacle, we develop a method to obtain a model that is free from an AR structure and behaves similarly to the original S2S models, based on a teacher-student learning framework. In our method, called "FastS2S-VC", the student model consists of encoder, decoder, and attention predictor. The attention predictor learns to predict attention distributions solely from source speech along with a target class index with the guidance of those predicted by the teacher model from both source and target speech. Thanks to this structure, the model is freed from an AR structure and allows for parallelization. Furthermore, we show that FastS2S-VC is suitable for real-time implementation based on a sliding-window approach, and describe how to make it run in real-time. Through speaker-identity and emotional-expression conversion experiments, we confirmed that FastS2S-VC was able to speed up the conversion process by 70 to 100 times compared to the original AR-type S2S-VC methods, without significantly degrading the audio quality and similarity to target speech. We also confirmed that the real-time version of FastS2S-VC can be run with a latency of 32 ms when run on a GPU.