 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Robust Unsupervised Contextual Biasing for Speech Recognition
Paper and Code
May 04, 2020
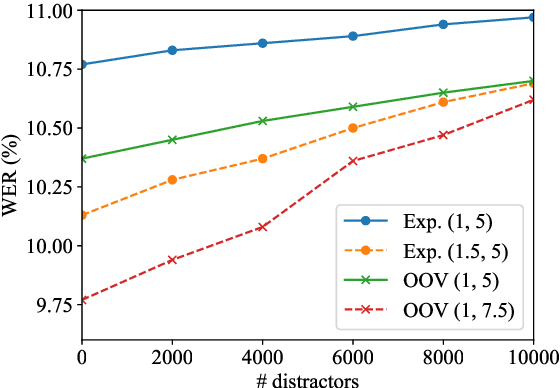


Automatic speech recognition (ASR) system is becoming a ubiquitous technology. Although its accuracy is closing the gap with that of human level under certain settings, one area that can further improve is to incorporate user-specific information or context to bias its prediction. A common framework is to dynamically construct a small language model from the provided contextual mini corpus and interpolate its score with the main language model during the decoding process. Here we propose an alternative approach that does not entail explicit contextual language model. Instead, we derive the bias score for every word in the system vocabulary from the training corpus. The method is unique in that 1) it does not require meta-data or class-label annotation for the context or the training corpus. 2) The bias score is proportional to the word's log-probability, thus not only would it bias the provided context, but also robust against irrelevant context (e.g. user mis-specified or in case where it is hard to quantify a tight scope). 3) The bias score for the entire vocabulary is pre-determined during the training stage, thereby eliminating computationally expensive language model construction during inference. We show significant improvement in recognition accuracy when the relevant context is available. Additionally, we also demonstrate that the proposed method exhibits high tolerance to false-triggering errors in the presence of irrelevant context.