 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Bayes-consistent nearest neighbors
Paper and Code
Oct 07, 2019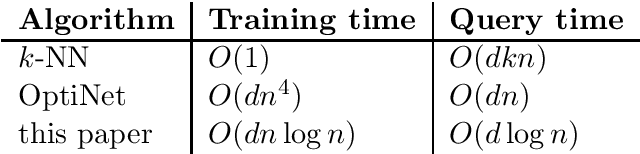
Research on nearest-neighbor methods tends to focus somewhat dichotomously either on the statistical or the computational aspects -- either on, say, Bayes consistency and rates of convergence or on techniques for speeding up the proximity search. This paper aims at bridging these realms: to reap the advantages of fast evaluation time while maintaining Bayes consistency, and further without sacrificing too much in the risk decay rate. We combine the locality-sensitive hashing (LSH) technique with a novel missing-mass argument to obtain a fast and Bayes-consistent classifier. Our algorithm's prediction runtime compares favorably against state of the art approximate NN methods, while maintaining Bayes-consistency and attaining rates comparable to minimax. On samples of size $n$ in $\R^d$, our pre-processing phase has runtime $O(d n \log n)$, while the evaluation phase has runtime $O(d\log n)$ per query point.