 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-Aware Job Scheduling for Multi-Job Federated Learning
Paper and Code
Jan 08, 2024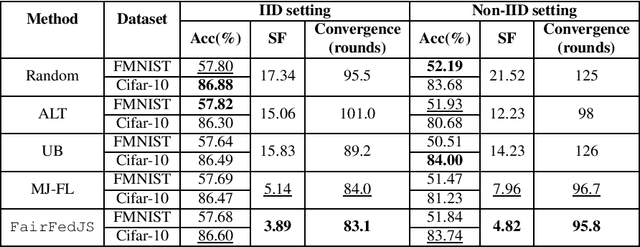
Federated learning (FL) enables multiple data owners (a.k.a. FL clients) to collaboratively train machine learning models without disclosing sensitive private data. Existing FL research mostly focuses on the monopoly scenario in which a single FL server selects a subset of FL clients to update their local models in each round of training. In practice, there can be multiple FL servers simultaneously trying to select clients from the same pool. In this paper, we propose a first-of-its-kind Fairness-aware Federated Job Scheduling (FairFedJS) approach to bridge this gap. Based on Lyapunov optimization, it ensures fair allocation of high-demand FL client datasets to FL jobs in need of them, by jointly considering the current demand and the job payment bids, in order to prevent prolonged waiting. Extensive experiments comparing FairFedJS against four state-of-the-art approaches on two datasets demonstrate its significant advantages. It outperforms the best baseline by 31.9% and 1.0% on average in terms of scheduling fairness and convergence time, respectively, while achieving comparable test accuracy.